Generative AI tem sido um dos principais tópicos de discussão este ano, atraindo tanto ceticismo quanto diferentes graus de otimismo ou pessimismo. Nossa experiência de trabalho, pesquisa e desenvolvimento de produtos que utilizam essa tecnologia nos levou ao nosso próprio ponto de vista. E estamos confiantes de que ela tem um profundo potencial para remodelar o desenvolvimento de software, bem como a educação. Embora a maioria dos usuários já esteja testemunhando os recursos de aplicativos como ChatGPT, Midjourney e Dall-e 3, transformando os fluxos de trabalho diários com melhorias significativas de produtividade, a perspectiva de dentro do campo é ainda mais surpreendente.
Para aqueles que estão diretamente envolvidos na IA generativa, o ritmo de desenvolvimento é de tirar o fôlego. Novos modelos, descobertas e avanços em ferramentas e plataformas de infraestrutura estão surgindo em um ritmo sem precedentes, com progressos notáveis ocorrendo quase semanalmente. Essa rápida evolução destaca não apenas o impacto imediato nas tarefas cotidianas, mas também o potencial de longo alcance do campo em um futuro não tão distante.
Para ilustrar o ritmo acelerado de desenvolvimento da IA generativa, considere os avanços feitos na mesma semana em que este artigo estava sendo escrito, no início de dezembro de 2023. O Google anunciou o Gemini, um modelo multimodal inovador que desafia o GPT-4 [15][16]. Ao mesmo tempo, a Mistral AI revelou o Mixtral 8x7b-32k, o primeiro modelo de “mistura de especialistas” de código aberto, por meio de um tweet enigmático [17]. A Together AI lançou o StripedHyena-7B, um modelo muito competente que se desvia da arquitetura tradicional de transformadores [18]. Além disso, os pesquisadores da Cornell introduziram o “QuIP#”, uma técnica para compactar modelos de 16 bits em representações de 2 bits com perda mínima de desempenho [19]. Esses desenvolvimentos, apenas um instantâneo do progresso semanal em andamento, destacam a evolução dinâmica do campo.
Termos como “multimodal”, “transformadores”, “mistura de especialistas” e “quantização” podem ser novos para alguns leitores. Para tornar nossa discussão mais acessível, reduziremos nosso foco aos conceitos básicos. Portanto, vamos começar com uma pergunta fundamental: O que é IA generativa?
Termos como “multimodal”, “transformadores”, “mistura de especialistas” e “quantização” podem ser novos para alguns leitores. Para tornar nossa discussão mais acessível, reduziremos nosso foco aos conceitos básicos. Então, vamos começar com uma pergunta fundamental: O que é IA generativa?
A IA generativa refere-se a sistemas de inteligência artificial que podem gerar novos conteúdos. Isso inclui tudo, desde escrever textos, compor músicas até gerar imagens ou vídeos realistas. Um avanço significativo nesse campo ocorreu com o advento de arquiteturas baseadas em transformadores e técnicas de aprendizagem profunda, que aumentaram muito os recursos e a eficiência desses sistemas de IA.
Quando nos referimos apenas a texto, usamos o termo Large Language Models ou LLMs. Por exemplo, o GPT-4 é um modelo de linguagem grande. O mesmo acontece com os modelos LLaMA (desenvolvido pela Meta), Claude-2 (desenvolvido pela Anthropic), PaLM-2 (desenvolvido pelo Google), Mistral (desenvolvido pela Mistral AI) e tantos outros que atualmente competem pelos lugares mais altos nas arenas de Chatbot (alguns exemplos [21][22]).
Há também outros tipos de modelos baseados em transformadores, como o Whisper da Open AI, que implementa o reconhecimento automático de fala (ASR) multilíngue de última geração, modelos multimodais, como o GPT-4V (GPT-4 + Vision) e o Gemini do Google, e modelos baseados em difusão, como o Stable Diffusion ou o mais recente SDXL Turbo, que implementa a geração de texto para imagem em tempo real.
De agora em diante, vamos restringir nosso escopo aos modelos de linguagem grandes ou LLMs. Eles são chamados de grandes porque sua arquitetura de aprendizagem profunda consiste em algo que se assemelha a uma vasta rede de conexões neurais, semelhante a um modelo simplificado do cérebro humano. Essas redes, compostas de bilhões de parâmetros, são treinadas com um objetivo aparentemente simples: prever o próximo token.
O estágio de treinamento de um LLM competitivo é caro e muito desafiador. Para uma boa introdução, consulte [9]. Grosso modo e simplificando:
1. A primeira etapa é obter um modelo básico, ou modelo mundial. Ou seja, um preditor de próximo token com base em todas as fontes de texto disponíveis. Esse modelo básico, por exemplo, quando alimentado (solicitado) com algo como “Bem-vindo ao coração da América do Sul, ao nosso amado país sem litoral. Welcome to” muito provavelmente preverá que a próxima palavra é “Bolívia” e poderá continuar gerando previsões do próximo token “, uma nação conhecida por sua rica cultura, beleza natural impressionante” e assim por diante.
2. A segunda etapa é treinar gradualmente o modelo básico usando um conjunto de dados menor de dados altamente selecionados. Normalmente, esse conjunto de dados se assemelha ao caso de uso pretendido. Por exemplo, para treinar um assistente como o ChatGPT, podemos usar um conjunto de interações entre um usuário e um agente.
3. Uma próxima etapa opcional é alinhar o modelo usando feedback humano. Às vezes chamada de RLHF (Reinforcement Learning from Human Feedback). Normalmente, essa etapa envolve solicitar que o modelo gere várias respostas para a mesma pergunta e pedir aos humanos que classifiquem a qualidade das respostas ou, em alguns casos, sinalizem as inadequadas. Esse feedback humano é retropropagado ao modelo para ajustar seus parâmetros, favorecendo as interações que os humanos consideram as melhores.
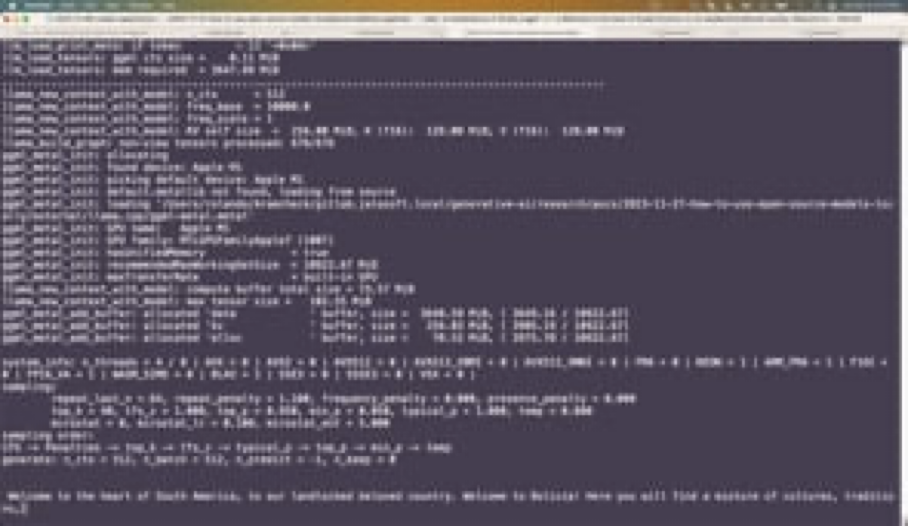
Portanto, em sua essência, um LLM é:
– Uma representação compactada do mundo, derivada de seus dados de texto de treinamento.
– Um preditor de próximo token altamente eficaz.
Esses dois recursos tornam os LLMs ferramentas eficientes de recuperação de conhecimento. Isso é verdade desde que o conhecimento esteja presente em seu corpus de aprendizado e não seja diluído nem inconsistente.
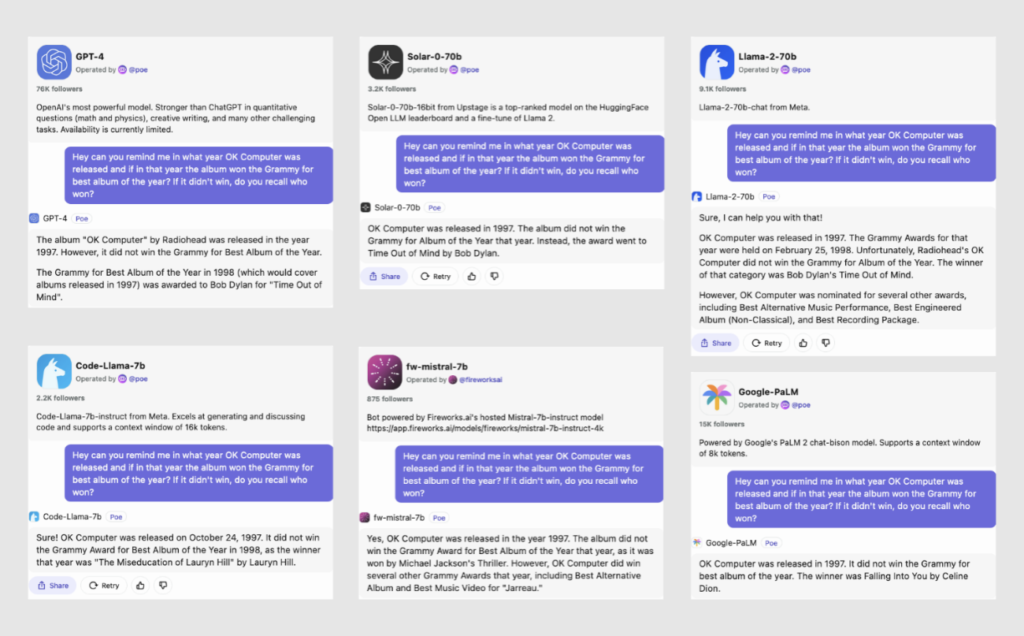
Ao avaliar o desempenho de vários modelos de IA na pergunta sobre o ano de lançamento de “OK Computer”, do Radiohead, e o prêmio Grammy daquele ano, observamos alguns resultados interessantes. A maioria dos modelos identifica corretamente 1997 como o ano de lançamento. Os três principais modelos – GPT-4, Solar e Llama-2-70B – também observam com precisão que Bob Dylan ganhou o Grammy de Melhor Álbum naquele ano. No entanto, com exceção do GPT-4, a maioria dos modelos demonstra imprecisões ou confunde os fatos ao fornecer informações históricas adicionais, ilustrando os desafios de se obter consistência factual perfeita nas respostas de IA.
O segundo recurso que podemos observar é que os modelos às vezes são sonhadores! Como eles são treinados para prever basicamente o próximo token e têm uma versão comprimida do mundo, eles geram conclusões de prompt com aparência plausível. Do lado positivo, essa característica ressalta o aspecto imaginativo da IA.
É interessante notar que, à medida que os LLMs aumentam de tamanho, há um fenômeno chamado “habilidades emergentes” que se refere a habilidades “não presentes” em modelos menores que começam a aparecer em modelos maiores que não são diretamente treinados para ter essas habilidades [10]. De repente, como uma pura consequência do tamanho, os modelos começam a seguir melhor as instruções, aprendem com apenas alguns exemplos, realizam raciocínio em várias etapas, aprendem a multiplicar números grandes e assim por diante [11][12][13].
Acontece que alguns desses modelos, em especial o GPT-4, mas também modelos como Mistral, Starcoder, Replit, Phind, CodeLlama e outros, são muito bons em codificação. E por “muito bons”, queremos dizer que eles podem não apenas entender e depurar códigos complexos, mas também escrever programas funcionais e eficientes em várias linguagens. Eles demonstram capacidade de compreender conceitos de programação, seguir estruturas lógicas e até mesmo oferecer soluções criativas de codificação que podem rivalizar com programadores humanos experientes.
Em nossa posição na Jala, com uma sólida experiência em desenvolvimento de software e educação que se estende por mais de duas décadas, reconhecemos a importância fundamental de compreender o impacto da IA generativa.
A Jala University, uma pedra angular de nossa visão, representa nosso compromisso com aqueles que nos confiam sua educação e com nossa região. Nesse sentido, entender como a IA generativa remodelará o setor de software e o cenário educacional torna-se não apenas relevante, mas essencial para nós.
Durante este ano (2023), vimos vislumbres do enorme potencial que essa tecnologia traz para o processo de desenvolvimento de software. Nossos engenheiros de software aprenderam a adotar as ferramentas e a usá-las com responsabilidade para maximizar sua produtividade. Também passamos por muitas dificuldades e testemunhamos a frustração de instrutores e alunos quando a tecnologia parecia estar se voltando contra nós.
Portanto, após uma longa introdução e sem tentar especular demais sobre o que o futuro pode trazer, queremos compartilhar as principais percepções que resumem nossa posição sobre a IA generativa.
- A IA generativa veio para ficar, os educadores e os alunos devem adotá-la de forma proativa.
É importante expor nossos alunos à tecnologia o mais cedo possível (de preferência, durante o primeiro semestre).
- Nós (universidade) precisamos reequilibrar ligeiramente os resultados de nossos alunos em relação às habilidades centradas no ser humano (pessoas).
Nos últimos 20 anos, nossa jornada educacional foi marcada por uma mudança dos modelos tradicionais focados na memorização e na repetição para o desenvolvimento do pensamento crítico e das habilidades de resolução de problemas.
À medida que caminhamos (ou corremos) em direção a um mundo em que a IA geradora complementa nossas habilidades diariamente, as habilidades de conhecimento serão menos relevantes e as habilidades centradas no ser humano serão significativamente mais importantes.
Já estamos muito alinhados com esse caminho, mas precisamos dobrar nossos esforços para que nossos alunos possam maximizar suas habilidades em pensamento crítico, colaboração, comunicação, resiliência, resolução de problemas, criatividade, inteligência emocional e a busca pela aprendizagem contínua.
Paradoxalmente, a IA generativa pode nos ajudar ou jogar contra.
- Aproveitar as ferramentas de IA geradora para alcançar os resultados de nossos alunos.
Em termos concretos:
a. Explorar e implementar a aprendizagem personalizada usando tutores de IA que possam complementar a experiência de aprendizagem em nossos cursos e, ao mesmo tempo, adaptar-se aos pontos fortes, pontos fracos, interesses e estilos de aprendizagem de cada aluno.
b. Explorar e implementar um suporte de tradução de idiomas em tempo real altamente eficiente, reduzindo a lacuna de comunicação que às vezes encontramos entre falantes nativos de inglês, espanhol e português.
c. Explorar e implementar sistemas automatizados de feedback de IA.
d. Garantir que a tecnologia seja acessível e esteja disponível para alunos e educadores.
- Reavaliação e adaptação contínuas.
Revisar e reavaliar regularmente nossas estratégias educacionais para garantir que elas permaneçam alinhadas com os últimos desenvolvimentos em IA generativa. Isso envolve a adaptação de nosso currículo, metodologias de ensino e ferramentas para permanecer na vanguarda das práticas educacionais orientadas por IA.
Ao encerrarmos este ano acadêmico e nos prepararmos para 2024, nosso compromisso com a educação e com a nossa região está mais forte do que nunca. Nossa jornada com a IA generativa está apenas começando, e prevemos uma maior integração dessas tecnologias para aprimorar o aprendizado e a pesquisa. Juntos, entramos em uma nova era de educação na Jala University, prontos para inovar e liderar em um mundo aumentado pela IA.
Referências
- “Language Modeling Is Compression”.
https://arxiv.org/abs/2309.10668 - “White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?”.
https://arxiv.org/abs/2311.13110 - “ChatGPT Is a Blurry JPEG of the Web”.
https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web - “Open AI Whisper”.
https://openai.com/research/whisper - “The two models fueling generative AI products: Transformers and diffusion models”.
https://www.gptechblog.com/generative-ai-models-transformers-diffusion-models/ - “Introducing SDXL Turbo: A Real-Time Text-to-Image Generation Model”.
https://stability.ai/news/stability-ai-sdxl-turbo - “LlaMA model card”.
https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md - “See the pitch memo that raised €105M for four-week-old startup Mistral”.
https://sifted.eu/articles/pitch-deck-mistral - “Intro to Large Language Models”. Andrej Karpathy.
https://www.youtube.com/watch?v=zjkBMFhNj_g - “Emergent Abilities of Large Language Models”.
https://www.assemblyai.com/blog/emergent-abilities-of-large-language-models/ - “Language Models are Few-Shot Learners”.
https://arxiv.org/pdf/2005.14165.pdf - “Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models”.
https://arxiv.org/abs/2206.04615 - “Emergent Abilities of Large Language Models”.
https://arxiv.org/pdf/2206.07682.pdf - “BigCode Models Leaderboard”.
https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard - “Google Gemini”
https://deepmind.google/technologies/gemini/#introduction - “Google launches Gemini—a powerful AI model it says can surpass GPT-4″
https://arstechnica.com/information-technology/2023/12/google-launches-gemini-a-powerful-ai-model-it-says-can-surpass-gpt-4/ - “Mixtral 8x7b-32k”
https://twitter.com/MistralAI/status/1733150512395038967?s=20 - “Paving the way to efficient architectures: StripedHyena-7B, open source models offering a glimpse into a world beyond Transformers”
https://www.together.ai/blog/stripedhyena-7b - “QuIP#: QuIP with Lattice Codebooks”
https://cornell-relaxml.github.io/quip-sharp/ - “Inside OpenAI’s Crisis Over the Future of Artificial Intelligence”
https://archive.is/HJS11 - “Chatbot arena leaderboard”
https://arena.lmsys.org/ - “Alpaca eval leaderboard”
https://tatsu-lab.github.io/alpaca_eval/
Este artigo foi aprimorado com insights e assistência de revisão de modelos de IA de fronteira, incluindo o GPT-4 da OpenAI e o Claude-2 100K da Anthropic.