The Symbolic Machine and the Paradox of Generating Intelligence
By Santiago Komadina Geffroy
January 8, 2026
Modern artificial intelligence (AI) arises from the intersection of computer science, mathematics, and linguistics1. At its core operate logic and formal languages 2; however, reducing intelligence to the logical-formal has shown persistent limits3. Symbolic AI based on rules did not achieve general intelligence: manipulating symbols did not guarantee understanding them4. In humans, language structures and conveys thought without exhausting it 5; in artificial systems, in contrast, we tend to equate linguistic generation with intelligence6.
In 1950, Turing shifted the question “Can machines think?” to a criterion of textual behavior (the Imitation Game)7. More than seven decades later, generative models—from GPT to Gemini or Claude—seem to fulfill this criterion of indistinguishability in broad domains8. The success, however, reignites the question: is linguistic generation a form of thought or a statistical simulacrum that confuses fluency with understanding? 9
Here we propose a cross-reading between the Turing machine and Chomsky’s generative grammar to illuminate the promise and the limit of generative AI: generating language without necessarily understanding it10. Furthermore, the contemporary irony is that we attempt to generate intelligence without fully understanding what intelligence itself is , we aspire to algorithmically produce that which we can barely define conceptually.
1. Turing and Language as Procedure
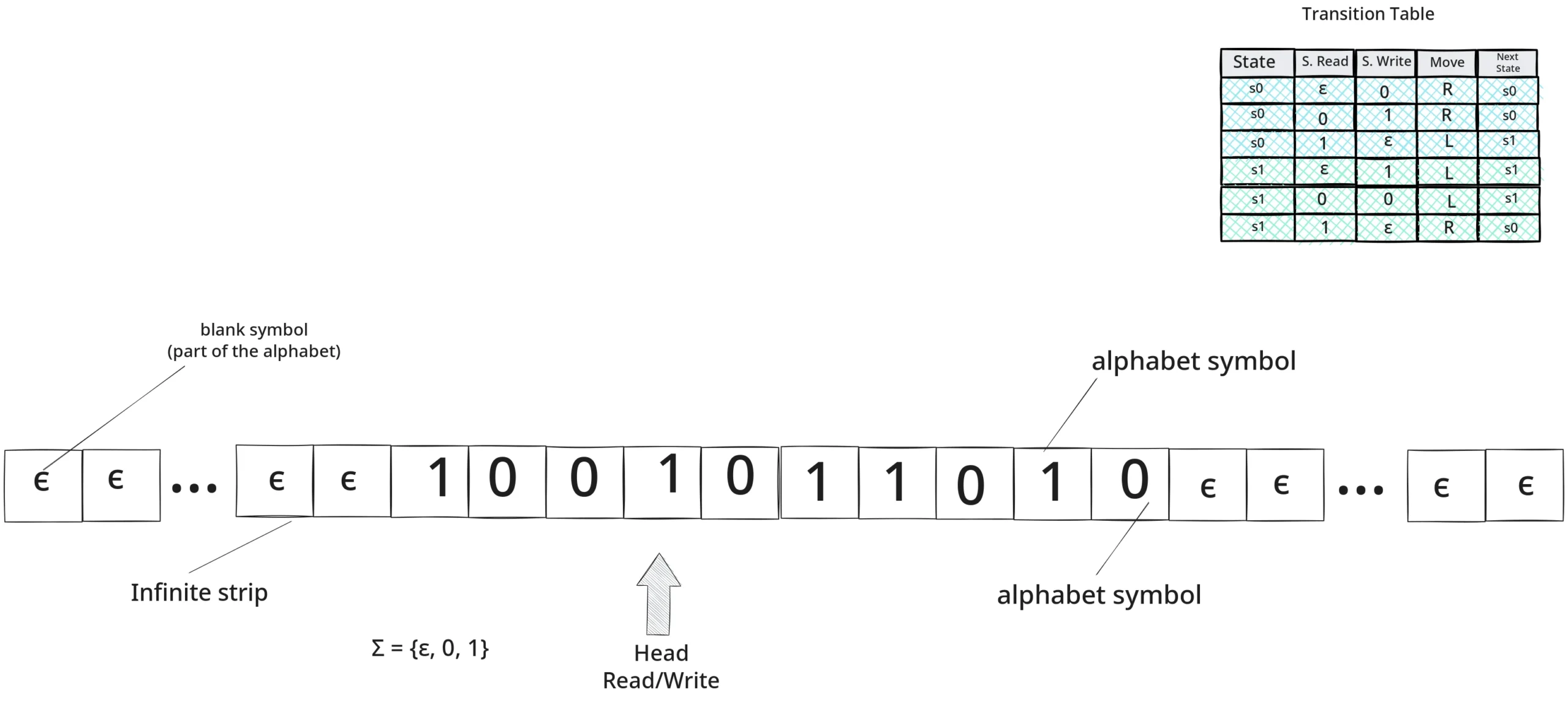
The Turing machine (1936) formalizes computability13. In its standard definition, an MT is a 7-tuple:
Where ($Q$) is the set of states, ($\Sigma$) the input alphabet, ($\Gamma$) the tape alphabet, ($\delta$) the transition function, ($q_0$) the initial state, and ($q_{accept}, q_{reject}$) the halting states14. With a theoretically infinite tape and a finite set of rules, Turing shows that every effective algorithm is, in principle, simulable15.
In terms of computation theory, it is convenient to distinguish decidability from enumerability: there are languages for which a procedure exists that decides acceptance or rejection in finite time (decidable), and others for which we can only enumerate the accepted elements without a guarantee of halting on the rejected ones (recursively enumerable)16. The Church-Turing Thesis is not a formal mathematical theorem—it relates an informal concept (“effective calculation”) with a formal one (Turing machine)—but it constitutes a universally accepted fundamental principle after almost a century of accumulated evidence: any effective calculation we can clearly describe is simulable by a Turing machine17. This enables the bridge to the theory of languages and automata: each formal system can be seen as a device that generates or recognizes well-formed strings18.
The Turing test transfers computation to the stage of language: if textual interaction is indistinguishable from human interaction, the machine passes as “thinking”19. Contemporary LLMs embody this procedural vision: speaking as calculating20.
2. Chomsky, Formal Languages, and their Equivalence with Machines
The Chomsky Hierarchy orders grammars by their generative power and correlates them with classes of automata22:

Note on Type 1: A Linearly Bounded Automaton (LBA) is essentially a Turing machine whose tape is restricted to a linear multiple of the input size27. This limitation captures the family of context-sensitive languages, where derivations may depend on the environment but are still subject to a memory resource bounded by the input28.
In standard notation, the language recognized by an automaton:
Generative grammar describes a device capable of producing well-formed sequences30. Chomsky interprets it as a cognitive faculty31; Turing, as a computational characterization32.
The infinite productivity of generative grammar—the capacity to generate and understand an unlimited number of sentences from finite rules 33—inspired the intuition that formal systems could capture the essence of language34. For decades, symbolic AI attempted to explicitly encode these rules: feature grammars, syntactic parsers, semantic ontologies35. The program assumed that describing linguistic competence was equivalent to implementing it36. Modern AI inherits the strong intuition that mind and language are modeled as symbolic manipulation governed by rules37.
However, the contemporary turn inverts the paradigm: rules are no longer programmed, they are learned38. Neural models are parametric automata whose expressive complexity can reach that of Type 0 languages 39, but they are induced from data instead of being specified by linguists40. Where Chomsky postulated innate universals, LLMs discover statistical regularities in massive corpora41. Where generative grammar sought underlying competence (the speaker’s tacit knowledge), transformers capture observable performance (the regularities of effective use)42.
This methodological rupture has profound consequences: we no longer formalize language and then implement it 43; we train systems to induce their own regularities44. The result is an implicit grammar, distributed across millions of parameters, which can generate fluid text without possessing an explicit model of syntax or semantics45. We have learned to generate linguistic intelligence without needing to specify it 46; the pending question is whether that generation constitutes genuine understanding or mere sophisticated simulation47.
The elegance of formal correspondence should not be confused with an ontology of meaning: that a class of languages is representable by an automaton does not imply that human language use is exhausted by that representation48. Furthermore, that a neural system simulates linguistic competence does not imply that it replicates the underlying cognitive mechanisms49.
3. Convergence and Rupture: Generating is Not Understanding
LLMs approximate probability distributions $p(w\_t|w_{t-1})$ over sequences using neural architectures (transformers) that can, in principle, model the complexity of Type 0 languages in the Chomsky hierarchy 50, albeit without implementing explicit rewrite rules51. Unlike formal grammars that operate through symbolic rewrite systems, LLMs are universal approximators that learn patterns from data: a statistical syntax trained on massive corpora52. They achieve fluency and local coherence without a guarantee of internal semantics53. If Chomskyan grammar aimed at competence (underlying knowledge), LLMs primarily capture performance (regularities of use) and signals of the world distilled from text54.
In the Chomskyan tradition, grammar is above all a mental faculty: a biological system with innate constraints that explains how humans acquire and manipulate syntactic structures55. In generative AI, in contrast, “grammar” is the operational name of a probability function over strings, parameterized by millions or billions of weights that adjust the likelihood of each token in context56. Both perspectives share a formal intuition, but differ in their ontology: the former refers to cognitive mechanisms 57; the latter, to statistical procedures58. The result is a statistical syntax without intentionality59. Generation is not equal to understanding60. Formal coherence does not necessarily imply referential grounding or a world-view in the human sense61.
Natural language is ambiguous by design62. Formal logic aspires to eliminate ambiguity 63; linguistic use thrives on it64. How do models obtain “meaning” without total disambiguation? 65Through relational density: meaning is approximated as a position in a space of relationships66. And it is precisely this functional dimension that the technical marvel of computational linguistics exploits: embeddings67. These are nothing more than vectorial representations of words learned by a statistical model68. After “learning” on enormous text corpora, embedding models capture both semantics and syntactic relationships69. Having vectors for words then allows us to perform mathematical operations on the words and their meanings70. This is how we have managed to translate strings of symbols that make sense to us humans, into a computable reality71. The “artificial” meaning comes from here72.
However, its evolution illustrates the transition from static to dynamic semantics73:
- Word2Vec and GloVe (2013-2014): Each word receives a single vector based on co-occurrences in the corpus74. The famous vectorial analogy “king – man + woman = queen” works because algebraic operations capture recurrent semantic relationships75. However, these models do not distinguish polysemy: “bank” (financial institution) and “bank” (seat) share the same vector76.
- Contextual Embeddings (ELMO, BERT, 2018): Each word receives a distinct vector according to its context77. “Bank” in “I went to the bank to deposit” and “I sat on the park bench” generate different representations78. The model attends to the environment to disambiguate79.
- Generative Transformers (GPT, 2018-): Multi-head attention mechanisms allow each token to dynamically modulate its representation based on all other relevant tokens in the sequence 80, integrating long-range dependencies that imitate grammatical agreement, anaphoric references, and thematic coherence81.
Embeddings condense semantic and syntactic regularities into high-dimensional vectors whose proximity reflects co-occurrence patterns and contextual transformations 82; they do not say what a thing is, but what it tends to appear with and how it changes when combined83. Attention mechanisms allow each decision to dynamically condition a token with respect to potentially distant others 84, integrating long-range dependencies that imitate agreements and anaphoric relationships85. So-called mechanistic interpretability has identified heads and circuits sensitive to grammatical and style features, proving that the models capture useful statistical structure86.
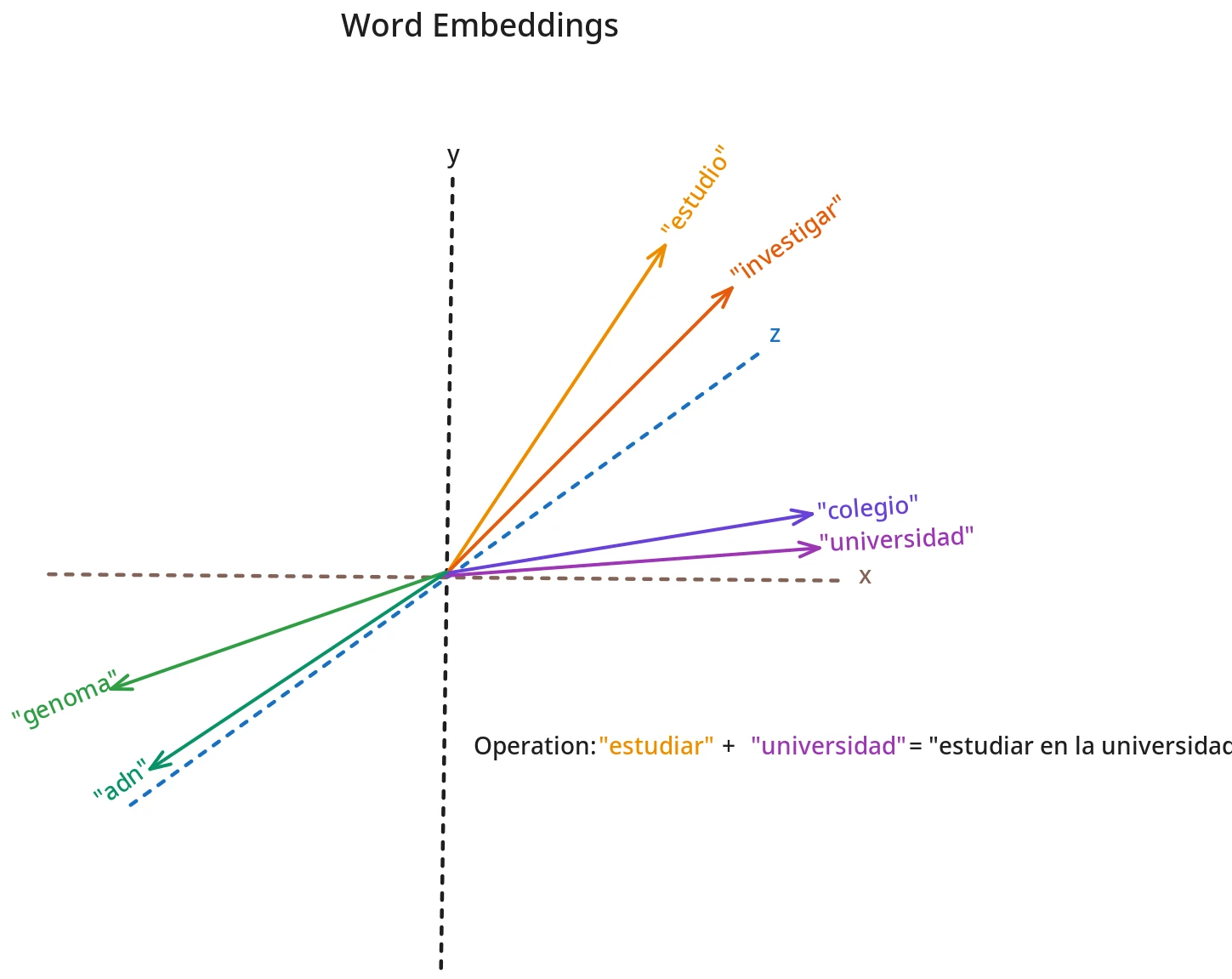
However, classic vectorial analogies work in frequent domains of the corpus 87, but break down under domain change or active polysemies: when switching from historical geography to contemporary geopolitics, or from everyday language to technical jargon, the semantic neighborhood varies and vectors drag spurious associations88 The phenomenon illustrates a strength (capturing local regularities) and a limit: fragility when faced with conceptual transfers that require re-grounding meanings89.
Furthermore, given their computational nature, we can perform mathematical operations on “the words.”] 90
Having rich representations is a necessary but not sufficient condition for situated understanding91. What emerges is powerful statistical competence 92, but without a direct ontological commitment to referents in the sense of autonomous perceptual experience 93—although recent multimodal models (CLIP, GPT-4V, Gemini) are beginning to integrate visual and textual signals, establishing incipient forms of perceptual grounding94.
4. Language between Structure, Symbol, and Culture
Chomsky’s achievement was formalizing language as a system of rules; its cost was abstracting the social dimension95. Sociolinguistics, pragmatics, and usage-based linguistics remind us that language is negotiated in communities of practice96. LLMs reincorporate culture via statistics: they absorb ideologies, biases, registers, and dialects without awareness97. They produce a synthetic culture: a reflection of historical distributions of our voices, sometimes with amplification of asymmetries98.
To say that language is symbolic is to affirm that its units mean by convention and relation (not by physical resemblance to their referents)99. This arbitrariness allows the same medium (text, audio, code) to express an infinite number of contents and styles100. That is why it is possible to model large families of practices with a single formalism: natural languages with their dialects, technical jargon, code, formulas, musical notation101. The symbolic dimension of language is what makes learning from heterogeneous corpora scalable102.
It does not follow from language being symbolic that there exists an operative Universal Grammar capable of recognizing everything by explicit rules103. We seek the formalism of intelligence (the “artificial”), but when we formalize without residue, we lose ambiguity 104, precisely the resource that living language exploits105. That language is alive does not imply anarchy: it implies regulated variation106. Rules (conventions) are learned and adjusted through use107. LLMs learn a snapshot of that variation: a model trained up to 2023 does not know the idiolect of 2025 without updating108. They are grammars frozen at their moment of training: they capture historical regularities of the corpus 109, but not its subsequent transformative dynamics without retraining, fine-tuning, or updating mechanisms like retrieval-augmented generation (RAG)110.
Large-scale models absorb cultural diversity without postulating explicit universals 111, and thus can simulate local consistencies in relatively closed domains while exhibiting grounding failures when practices, referents, or norms change112. Their notable functional efficacy does not constitute evidence of understanding 113: rather, it reveals the power of correlations114. Similarly, the biases they reproduce are not a simple “bug” that can be corrected a posteriori 115115, but a cultural effect of statistics: the distillation of historical distributions with their asymmetries116116116. They simulate consistency in closed domains, but fail in grounding when practices, referents, or norms change117. Their functional success does not prove understanding; their bias is not a merely technical “bug,” but a cultural effect of statistics118.
5. Beyond the Turing Test: Contemporary Criteria and Limits
Today we evaluate systems with complementary tests: Winograd/Winoground (references), ARC (abstraction and composition), BIG-bench, MMLU (knowledge and reasoning), and even ARC-AGI (the Holy Grail of current AI, being general), among others119. The panorama is mixed: notable advancements in statistical competence coexist with limits in systematic generalization, semantic grounding, and situated adaptation120. The leap from prediction to interpretation remains the bottleneck121.
In recent years, evaluations of grounding (temporal, factual, and multimodal) and protocols for using tools that connect the model with search engines, databases, or calculators have emerged122. These approaches improve accuracy when the task requires verifying or updating facts 123, but they also transfer part of the intelligence to the orchestration: deciding when to consult, which source to use, and how to reconcile conflicting evidence124. In parallel, work on emergent communication in reinforcement learning environments shows that agents can develop codes useful for their purposes, although they are rarely compositional and transferable to human practices without tutoring125.
A critic might argue: “Babies also acquire language through massive exposure to linguistic input, detecting statistical patterns in the speech around them. If humans learn this way and develop understanding, why wouldn’t LLMs, which do essentially the same thing with more data, have it?” 126
The objection is serious and deserves a careful answer. The differences are not merely quantitative (more data, more parameters), but qualitative127:
- Multimodal Grounding: Children learn language simultaneously with direct perceptual experience of the world128. When they hear “ball,” they see, touch, and throw balls129. The word is anchored in recurrent sensorimotor experiences130. Purely textual LLMs lack this triangulation 131; recent multimodal models (GPT-4V, Gemini) are beginning to close this gap, but still without the richness of corporeal experience132.
- Causal Models of the World: Humans develop intuitive physics (objects do not disappear, they fall down), intuitive psychology (agents have intentions), intuitive biology (living things grow and die)133. These causal models structure linguistic understanding134. An LLM can predict that “if you drop a glass, it breaks,” but not because it understands gravity or fragility, but because that sequence is frequent in its data135.
- Intrinsic Motivation and Situated Experience: Children learn language in contexts with real communicative purpose: asking, sharing attention, negotiating136. Every linguistic act has consequences in the social world137. LLMs are trained on a technical objective (predicting the next token) without agency or existential consequence of their “speech acts”138.
- Continuous Learning and Adaptation: Humans constantly update their understanding of language in interaction with the changing environment139. A child learning “dinosaur” adjusts their concept by visiting a museum, reading books, watching movies140. An LLM frozen at its training checkpoint does not evolve with the world141.
That humans and LLMs share statistical mechanisms in linguistic processing does not imply they share understanding142. The difference lies in the causal and perceptual grounding, motivated agency, and experiential continuity143. LLMs are systems that have learned to imitate linguistic competence without developing the cognitive preconditions that sustain it in humans144.
However, it is appropriate to recognize an epistemic limit to the previous argument145. The four pointed differences (multimodal grounding, causal models, intrinsic motivation, continuous learning) describe observable external conditions, not internal states of understanding146. We face here the classic problem of other minds: we do not have direct access to the subjective experience of any human or artificial system beyond our own consciousness147.
When we affirm that a child “understands” the word “ball” because they have seen, touched, and thrown it, we infer that understanding from their coherent behavior in varied contexts 148: they can ask for the ball, distinguish it from other objects, use it appropriately149. But the phenomenological experience of the child—the “what it feels like” to understand—is inaccessible to us150. The same applies to LLMs: we can document their systematic failures (fragility to domain changes, regression to frequent patterns) 151, but we cannot categorically rule out that some form of emergent “understanding” exists in their internal layers 152, distinct from the human one but functional in its own way153. Furthermore, perhaps humans are also, at some fundamental level, sophisticated statistical approximators whose “understanding” is not qualitatively different 154, but only quantitatively richer due to our multimodal and evolutionary grounding155. This hypothesis, although speculative, cannot be empirically refuted from outside the system156.
Does this uncertainty matter? Pragmatically, not for engineering purposes157. What matters are the measurable consequences158:
- Robustness: Does the system maintain coherence under variations in context, domain, and formulation? 159
- Adaptability: Can it update its responses to new evidence without complete retraining? 160
- Grounding: Does it verify its statements against external sources or generate plausible fiction? 161
- Transparency: Can we audit its decisions and correct systematic biases? 162
From this functionalist perspective, the relevant question is not “does it truly understand?” but “does it behave as if it understood in a reliable, adaptable, and auditable manner?” 163The current answer is: in closed domains, often yes; in open or changing domains, systematically no164. We adopt a pragmatic agnosticism about the internal understanding of LLMs165. We do not affirm that they lack all form of “understanding” 166, but given their observable failures, they do not meet robust functional criteria for situated understanding167. The burden of proof lies in demonstrating generalizable reliability, not in postulating inaccessible internal states168.
6. Conclusion: Towards a Critical Theory of Artificial Generation
Turing’s program presents language as a procedure and offers textual indistinguishability as a pragmatic criterion169; Chomsky’s conceives it as a faculty with formal constraints that explain structural productivity at the cost of abstracting the social 170; generative AI treats it as a statistical-cultural model capable of capturing correlations and styles without autonomous experiential grounding171. These three perspectives are not mutually exclusive, but neither are they reducible to one another172.
The contemporary project of generating intelligence through massive statistical learning reveals a foundational paradox: we seek to produce what we cannot define173. What exactly is the intelligence we aspire to generate? 174 Capacity to solve problems, adaptability to the unforeseen, situated understanding, phenomenological consciousness? 175Each proposed criterion—Turing test, academic benchmarks, performance on specific tasks—captures partial dimensions without exhausting the phenomenon176. We have learned to generate intelligent behavior in delimited domains 177, but the question of whether that constitutes genuine intelligence or sophisticated simulation remains open 178—and perhaps, from a pragmatic perspective, is undecidable179.
Generating text is not equivalent to predicting meaning 180: at most, it participates in its negotiation in a limited way181. The aspiration to “perfect prediction” is not only unattainable but conceptually flawed when faced with an object in constant change182. Therefore, intelligence is not synonymous with language 183: generative AI today functions as a computational interface between our intentions and the machine 184, translating instructions into operations through natural or formal languages185. It is an automated statistical competence 186that simulates coherence in finite formal spaces without its own semantic horizon 187in the sense of autonomous agency188.
The most promising horizon is not about “passing off” machines as human 189, but about co-designing models that evolve with us 190, mindful of the permanent negotiation between structure, culture, and novelty191. Let us measure artificial intelligence where prediction stumbles and interpretation begins 192—in situated adaptation, grounding to the world, and responsibility for the consequences of what is said193.
References
Avramides, A. (2001). Other Minds. Routledge. Bender, E., & Koller, A. (2020).
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of
Data. ACL. Bender, E., Gebru, T., et al. (2021). On the Dangers of Stochastic Parrots. FAccT. Bybee, J. (2010). Language, Usage and Cognition. CUP.
Chomsky, N. (1957). Syntactic Structures. Mouton. Chomsky, N. (1965). Aspects of the Theory of Syntax. MIT Press. Clark, A. (1997). Being There. MIT
Press. Dennett, D. (1991). Consciousness Explained. Little, Brown. Floridi, L.
(2019). The Logic of Information. OUP. Halliday, M. A. K. (1978). Language
9
as Social Semiotic. Edward Arnold. Harnad, S. (1990). The Symbol Grounding
Problem. Physica D, 42(1–3), 335–346. Hopper, P. J. (1987). Emergent Grammar. BLS 13, 139–157. Hymes, D. (1972). On Communicative Competence.
In Pride & Holmes (eds.), Sociolinguistics. Lakoff, G. (1987). Women, Fire,
and Dangerous Things. U. Chicago Press. Lazaridou, A., Peysakhovich, A., &
Baroni, M. (2016). Multi‑Agent Cooperation and the Emergence of (Natural)
Language. ICLR. Lenneberg, E. (1967). Biological Foundations of Language.
Wiley. Mikolov, T., et al. (2013). Efficient Estimation of Word Representations
in Vector Space. arXiv. [Word2Vec] Mordatch, I., & Abbeel, P. (2018). Emergence of Grounded Compositional Language in Multi‑Agent Populations. AAAI.
Pennington, J., Socher, R., & Manning, C. (2014). GloVe: Global Vectors for
Word Representation. EMNLP. Peters, M., et al. (2018). Deep Contextualized
Word Representations. NAACL. [ELMo] Radford, A., et al. (2018). Improving
Language Understanding by Generative Pre-Training. OpenAI. [GPT] Schick,
T., Dwivedi‑Yu, J., et al. (2023). Toolformer: Language Models Can Teach
Themselves to Use Tools. arXiv. Yao, S., et al. (2023). ReAct: Synergizing
Reasoning and Acting in Language Models. ICLR. Zhou, B., et al. (2021). TimeDial: Temporal Commonsense Reasoning in Dialog. EMNLP. Marcus, G.,
& Davis, E. (2019). Rebooting AI. Pantheon. Searle, J. (1980). Minds, Brains,
and Programs. BBS, 3(3), 417–424. Tomasello, M. (2003). Constructing a
Language. Harvard. Turing, A. (1950). Computing Machinery and Intelligence.
Mind, 59(236), 433–460. Vaswani, A., et al. (2017). Attention Is All You Need.
NeurIPS. [Transformer architecture
This article was written in Spanish and translated into English and Portuguese with the help of ChatGPT.
Discover more articles of your interest!
Go back
