A Máquina Simbólica e o Paradoxo de Gerar Inteligência
Por Santiago Komadina Geffroy
Janeiro 8, 2026
A inteligência artificial moderna surge do cruzamento entre informática, matemática e linguística1. Em sua base, operam a lógica e as linguagens formais2; no entanto, reduzir a inteligência ao lógico-formal tem demonstrado limites persistentes3. A IA simbólica baseada em regras não alcançou uma inteligência geral: manipular símbolos não garantiu compreendê-los4.
Em humanos, a linguagem estrutura e veicula o pensamento sem esgotá-lo 5; em sistemas artificiais, em contraste, tendemos a equiparar a geração linguística com a inteligência6. Em 1950, Turing desloca a pergunta “Máquinas podem pensar?” para um critério de conduta textual (o Jogo da Imitação)7. Mais de sete décadas depois, os modelos generativos — de GPT a Gemini ou Claude — parecem cumprir esse critério de indistinguibilidade em amplos domínios8.
O sucesso, porém, reativa a questão: a geração linguística é uma forma de pensamento ou um simulacro estatístico que confunde fluência com entendimento? 9
Aqui propomos uma leitura cruzada entre a Máquina de Turing e a gramática generativa de Chomsky para iluminar a promessa e o limite da IA generativa: gerar linguagem sem necessariamente compreendê-la10. Mais ainda: a ironia contemporânea consiste no fato de que tentamos gerar inteligência sem compreender totalmente o que é a própria inteligência 1111; aspiramos a produzir algoritmicamente aquilo que mal podemos definir conceitualmente12121212.
1. Turing e a Linguagem como Procedimento
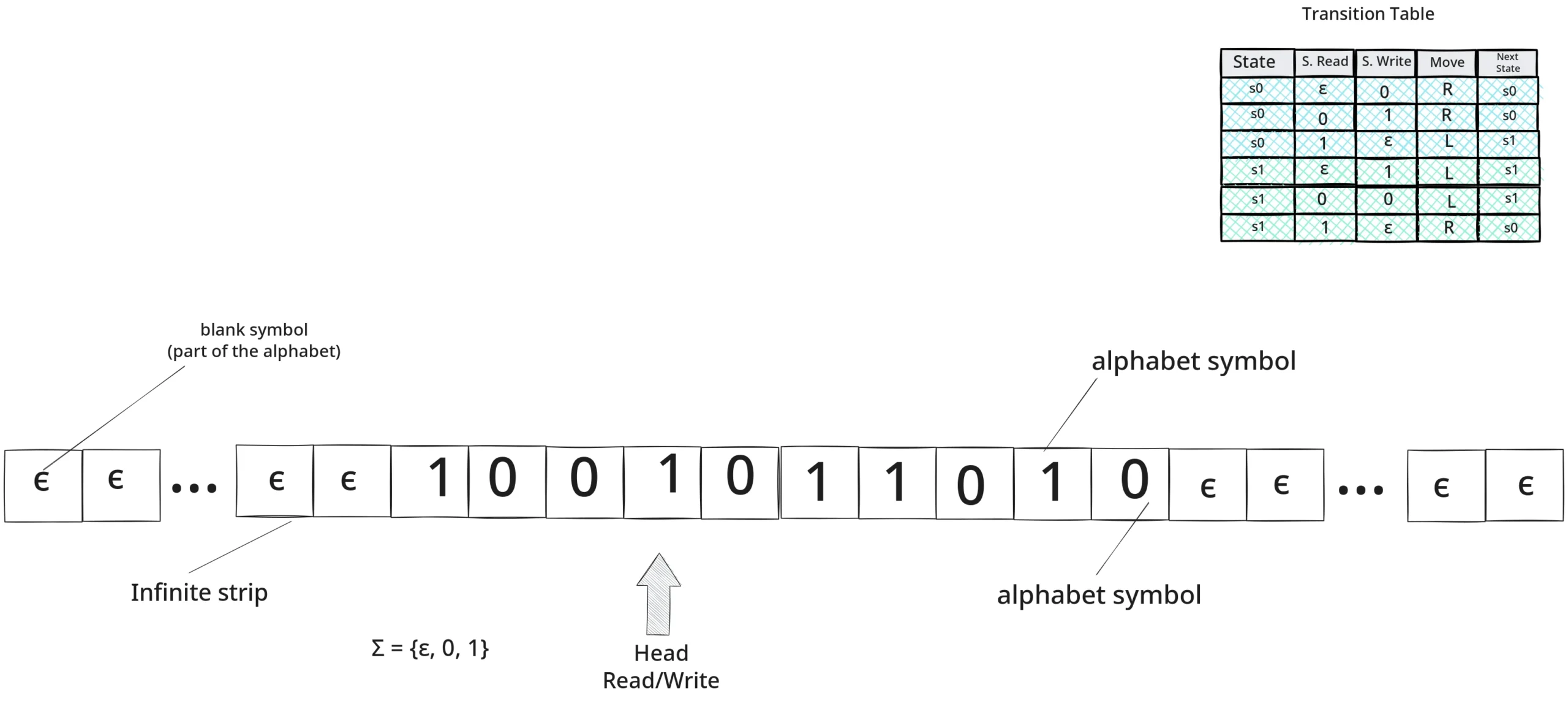
A Máquina de Turing (1936) formaliza a computabilidade13. Em sua definição padrão, uma MT é uma 7-tupla:
Onde $(Q)$ é o conjunto de estados, $(\Sigma)$ o alfabeto de entrada, $(\Gamma)$ o alfabeto de fita, $(\delta)$ a função de transição, $(q_0)$ o estado inicial e $(q_{aceita}, q_{rejeita})$ os estados de parada14. Com uma fita teoricamente infinita e um conjunto finito de regras, Turing mostra que todo algoritmo efetivo é, em princípio, simulável15.
Em termos de teoria da computação, convém distinguir decidibilidade de enumerabilidade: há linguagens para as quais existe um procedimento que decide aceitação ou rejeição em tempo finito (decidíveis), e outras para as quais só podemos enumerar os elementos aceitos sem garantia de parar nos rejeitados (recursivamente enumeráveis)16. A Tese de Church-Turing não é um teorema matemático formal — relaciona um conceito informal (“cálculo efetivo”) com um formal (Máquina de Turing) — mas constitui um princípio fundamental universalmente aceito após quase um século de evidência acumulada: todo cálculo efetivo que possamos descrever com clareza é simulável por uma Máquina de Turing17.
Isso habilita a ponte com a teoria de linguagens e autômatos 18: cada sistema formal pode ser visto como um dispositivo que gera ou reconhece cadeias bem formadas19. O Teste de Turing transfere a computação para o teatro da linguagem 20: se a interação textual é indistinguível da humana, a máquina passa por “pensante”21. Os LLMs contemporâneos incorporam essa visão procedural 22: falar como calcular23.
2. Chomsky, as Linguagens Formais e sua Equivalência com Máquinas
A Hierarquia de Chomsky ordena gramáticas por seu poder generativo e as corresponde com classes de autômatos25:

Nota sobre o Tipo 1: Um autômato linearmente acotado (LBA) é essencialmente uma máquina de Turing cuja fita fica restrita a um múltiplo linear do tamanho da entrada31. Essa limitação captura a família de linguagens sensíveis ao contexto, onde as derivações podem depender do entorno, mas continuam sujeitas a um recurso de memória limitado pela entrada32.
Em notação padrão, a linguagem reconhecida por um autômato $(M)$ é:
A gramática generativa descreve um dispositivo capaz de produzir sequências bem formadas34. Chomsky a interpreta como faculdade cognitiva35; Turing, como caracterização computacional36.
A produtividade infinita da gramática generativa — a capacidade de gerar e compreender um número ilimitado de orações a partir de regras finitas — inspirou a intuição de que sistemas formais poderiam capturar a essência da linguagem37. Durante décadas, a IA simbólica tentou codificar essas regras explicitamente: gramáticas de traços, parsers sintáticos, ontologias semânticas38. O programa assumia que descrever a competência linguística equivalia a implementá-la39. A IA moderna herda a forte intuição de que mente e linguagem se modelam como manipulação simbólica regida por regras40.
No entanto, a guinada contemporânea inverte o paradigma: as regras já não se programam, são aprendidas41. Os modelos neurais são autômatos paramétricos cuja complexidade expressiva pode alcançar a de linguagens de Tipo 0, mas induzidos a partir de dados em vez de especificados por linguistas42. Onde Chomsky postulou universais inatos, os LLMs descobrem regularidades estatísticas em corpus massivos43. Onde a gramática generativa buscava competência subjacente (o conhecimento tácito do falante), os transformers capturam performance observável (as regularidades do uso efetivo)44.
Essa ruptura metodológica tem consequências profundas: já não formalizamos a linguagem para depois implementá-la 45; treinamos sistemas para que induzam suas próprias regularidades46. O resultado é uma gramática implícita, distribuída em milhões de parâmetros, que pode gerar texto fluído sem possuir um modelo explícito de sintaxe ou semântica47. Aprendemos a gerar inteligência linguística sem a necessidade de especificá-la 48; a pergunta pendente é se essa geração constitui genuína compreensão ou mera simulação sofisticada49.
A elegância da correspondência formal não deve ser confundida com uma ontologia do significado 50: o fato de uma classe de linguagens ser representável por um autômato não implica que o uso humano da linguagem se esgote nessa representação51. Mais ainda: o fato de um sistema neural simular competência linguística não implica que replique os mecanismos cognitivos subjacentes52.
3. Convergência e Ruptura: Gerar Não É Compreender
Os LLMs aproximam distribuições de probabilidade $p(w_t|w_{t-1})$ sobre sequências mediante arquiteturas neurais (transformers) que, em princípio, podem modelar a complexidade de linguagens de Tipo 0 na hierarquia de Chomsky, embora sem implementar regras de reescrita explícitas53. Diferente das gramáticas formais que operam mediante sistemas de reescrita simbólica, os LLMs são aproximadores universais que aprendem padrões dos dados 54: uma sintaxe estatística treinada em corpora massivos55.
Eles alcançam fluidez e coerência local sem garantia de semântica interna56. Se a gramática chomskyana apontava para a competência (conhecimento subjacente), os LLMs capturam sobretudo performance (regularidades de uso) e sinais de mundo destilados do texto57.
Na tradição chomskyana, a gramática é antes de tudo uma faculdade mental 58: um sistema biológico com restrições inatas que explica como os humanos adquirem e manipulam estruturas sintáticas59. Na IA generativa, em contraste, “gramática” é o nome operacional de uma função de probabilidade sobre cadeias, parametrizada por milhões ou bilhões de pesos que ajustam a verossimilhança de cada token em contexto60. Ambas as perspectivas compartilham uma intuição formal, mas diferem em sua ontologia: a primeira remete a mecanismos cognitivos 61; a segunda, a procedimentos estatísticos62. Resultado: uma sintaxe estatística sem intencionalidade63. Geração não é igual a compreensão64. O fato de existir coerência formal não implica necessariamente ancoragem referencial nem visão de mundo no sentido humano65.
A língua natural é ambígua por design66. A lógica formal aspira a eliminar a ambiguidade 67; o uso linguístico prospera nela68. Como os modelos obtêm “sentido” sem desambiguação total? 69Por densidade relacional: o significado é aproximado como posição em um espaço de relações70. E é justamente esta dimensão funcional que explora uma das maravilhas técnicas da linguística computacional: os embeddings71. Estes não são mais do que representações vetoriais de palavras aprendidas por um modelo estatístico72. Depois de “aprender” sobre enormes corpus de texto, os modelos de embeddings capturam tanto semântica quanto relações sintáticas73. Ter vetores para as palavras nos permite então realizar operações matemáticas sobre as palavras e seus sentidos74. Assim conseguimos traduzir cadeias de símbolos que para nós, humanos, fazem sentido, para uma realidade computável75. O sentido “artificial” vem daqui76.
No entanto, sua evolução ilustra o passo de uma semântica estática a uma dinâmica77:
- Word2Vec e GloVe (2013-2014): Cada palavra recebe um único vetor baseado em coocorrências no corpus78. A famosa analogia vetorial “rei – homem + mulher = rainha” funciona porque as operações algébricas capturam relações semânticas recorrentes79. No entanto, esses modelos não distinguem polissemias: “banco” (entidade financeira) e “banco” (assento) compartilham o mesmo vetor80.
- Embeddings contextuais (ELMO, BERT, 2018): Cada palavra recebe um vetor distinto segundo seu contexto81. “Banco” em “fui ao banco depositar” e “sentei-me no banco do parque” geram representações diferentes82. O modelo atende ao entorno para desambiguar83.
- Transformers generativos (GPT, 2018-): Os mecanismos de atenção multi-cabeça permitem que cada token module dinamicamente sua representação em função de todos os demais tokens relevantes na sequência, integrando dependências de longo alcance que imitam concordância gramatical, referências anafóricas e coerência temática84.
Os embeddings condensam regularidades semânticas e sintáticas em vetores de alta dimensão cuja proximidade reflete padrões de coocorrência e transformações contextuais 85; não dizem o que uma coisa é, mas com o que ela tende a aparecer e como se modifica ao se combinar86. Os mecanismos de atenção permitem que cada decisão condicione dinamicamente um token em relação a outros potencialmente distantes, integrando dependências de longo alcance que imitam acordos e relações anafóricas87. A chamada interpretabilidade mecanicista identificou cabeças e circuitos sensíveis a traços gramaticais e de estilo, prova de que os modelos capturam estrutura estatística útil88.
No entanto, as analogias vetoriais clássicas funcionam em domínios frequentes do corpus, mas se rompem sob mudança de domínio ou polissemias ativas 89: ao passar de geografia histórica para geopolítica contemporânea, ou de linguagem cotidiana a jargão técnico, a vizinhança semântica varia e os vetores arrastam associações espúrias90. O fenômeno ilustra uma fortaleza (capturar regularidades locais) e um limite: a fragilidade diante de translações conceituais que exigem reancorar significados91.
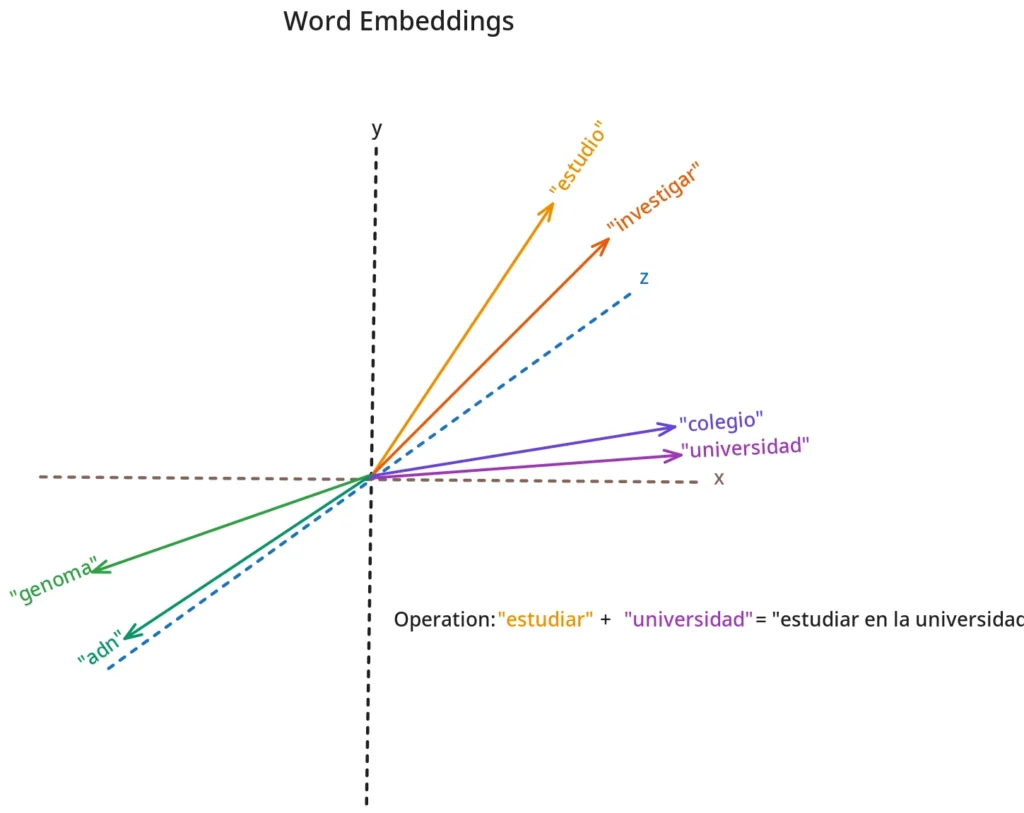
Seguindo essa lógica, cada palavra do nosso vocabulário tem um vetor de embedding aprendido que a posiciona deterministicamente em seu espaço latente (de dimensionalidade = ao tamanho do vocabulário)92. Dessa maneira, vetores similares indicam relações de proximidade semântica/sintática93. Além disso, dada a natureza computacional destes, podemos realizar operações matemáticas sobre “as palavras”94.]
Dispor de representações ricas é condição necessária, mas não suficiente, para a compreensão situada95. O que emerge é uma competência estatística poderosa, mas sem compromisso ontológico direto com referentes no sentido de experiência perceptual autônoma 96— embora modelos multimodais recentes (CLIP, GPT-4V, Gemini) comecem a integrar sinais visuais e textuais, estabelecendo formas incipientes de ancoragem perceptual97.
4. A Linguagem entre Estrutura, Símbolo e Cultura
O feito de Chomsky foi formalizar a linguagem como sistema de regras; seu custo foi abstrair a dimensão social98. A sociolinguística, a pragmática e a linguística do uso lembram que a linguagem é negociada em comunidades de prática99. Os LLMs reincorporam cultura por via estatística: absorvem ideologias, vieses, registros e dialetos sem consciência100. Produzem uma cultura sintética 101: reflexo de distribuições históricas de nossas vozes, às vezes com amplificação de assimetrias102.
Dizer que a linguagem é simbólica é afirmar que suas unidades significam por convenção e relação (não por semelhança física com seus referentes)103. Essa arbitrariedade permite que o mesmo suporte (texto, áudio, código) expresse infinidade de conteúdos e estilos104. Por isso é possível modelar com um único formalismo grandes famílias de práticas: idiomas naturais com seus dialetos, jargão técnico, código, fórmulas, notação musical… A dimensão simbólica da linguagem é a que torna escalável a aprendizagem a partir de corpus heterogêneos105.
Do fato de a linguagem ser simbólica não se segue que exista uma Gramática Universal operativa capaz de reconhecer tudo por regras explícitas106. Buscamos o formalismo da inteligência (o “artificial”), mas quando formalizamos sem resíduo perdemos ambiguidade, precisamente o recurso que a linguagem viva explora107. Que a língua esteja viva não implica anarquia: implica variação regulada108. As regras (convenções) são aprendidas e ajustadas em uso109.
Os LLMs aprendem um instantâneo dessa variação 110: um modelo treinado até 2023 não conhece o idioleto de 2025 sem atualização111. São gramáticas congeladas em seu momento de treinamento 112: capturam regularidades históricas do corpus, mas não sua dinâmica transformadora posterior sem retreinamento, fine-tuning ou mecanismos de atualização como retrieval-augmented generation (RAG)113.
Os modelos em grande escala absorvem diversidade cultural sem postular universais explícitos 114, e por isso podem simular consistências locais em domínios relativamente fechados ao mesmo tempo em que exibem falhas de ancoragem quando mudam práticas, referentes ou normas115. Sua notável eficácia funcional não constitui evidência de compreensão 116: revela, antes, o poder das correlações117. Da mesma forma, os vieses que reproduzem não são um simples “bug” corrigível a posteriori, mas um efeito cultural da estatística: a destilação de distribuições históricas com suas assimetrias118118118. Simulam consistência em domínios fechados, mas falham em ancoragem quando mudam práticas, referentes ou normas119. Seu sucesso funcional não prova compreensão; seu viés não é um “bug” meramente técnico, mas um efeito cultural da estatística120.
5. Além do Teste de Turing: Critérios e Limites Contemporâneos
Hoje avaliamos sistemas com provas complementares 121: Winograd/Winoground (referências), ARC (abstração e composição), BIG-bench, MMLU (conhecimento e raciocínio) e até ARC-AGI (o Santo Graal da IA atual, ser geral), entre outros122. O panorama é misto: avanços notáveis em competência estatística convivem com limites em generalização sistemática, ancoragem semântica e adaptação situada123. O salto de predição para interpretação continua sendo o gargalo124.
Nos últimos anos surgiram avaliações de ancoragem (temporal, factual e multimodal) e protocolos de uso de ferramentas que conectam o modelo com buscadores, bases de dados ou calculadoras125. Esses enfoques melhoram a precisão quando a tarefa exige verificar ou atualizar fatos, mas também transferem parte da inteligência para a orquestração 126: decidir quando consultar, qual fonte utilizar e como reconciliar evidências conflitantes127. Em paralelo, trabalhos sobre comunicação emergente em entornos de aprendizagem por reforço mostram que agentes podem desenvolver códigos úteis para seus fins, embora raramente composicionais e transferíveis a práticas humanas sem tutoria128.
Um crítico poderia argumentar: “Os bebês também adquirem a linguagem por exposição massiva a input linguístico, detectando padrões estatísticos na fala de seu entorno129. Se os humanos aprendemos assim e desenvolvemos compreensão, por que os LLMs, que fazem essencialmente o mesmo com mais dados, não a teriam?” 130
A objeção é séria e merece uma resposta cuidadosa131. As diferenças não são meramente quantitativas (mais dados, mais parâmetros), mas qualitativas132:
- Ancoragem multimodal: As crianças aprendem linguagem simultaneamente com experiência perceptual direta do mundo133. Quando ouvem “bola”, veem, tocam, lançam bolas134. A palavra se ancora em experiências sensório-motoras recorrentes135. Os LLMs puramente textuais carecem desta triangulação 136; modelos multimodais recentes (GPT-4V, Gemini) começam a fechar esta lacuna, mas ainda sem a riqueza da experiência corpórea137.
- Modelos causais do mundo: Os humanos desenvolvem física intuitiva (os objetos não desaparecem, caem), psicologia intuitiva (os agentes têm intenções), biologia intuitiva (os seres vivos crescem e morrem)138. Esses modelos causais estruturam a compreensão linguística139. Um LLM pode predizer que “se você soltar um copo, ele quebra”, mas não porque entenda gravidade ou fragilidade, mas porque essa sequência é frequente em seus dados140.
- Motivação intrínseca e experiência situada: As crianças aprendem linguagem em contextos com propósito comunicativo real: pedir, compartilhar atenção, negociar141. Cada ato linguístico tem consequências no mundo social142. Os LLMs são treinados em um objetivo técnico (predizer o próximo token) sem agência nem consequência existencial de seus “atos de fala”143.
- Aprendizagem contínua e adaptação: Os humanos atualizam constantemente sua compreensão da linguagem em interação com o entorno mutável144. Uma criança que aprende “dinossauro” ajusta seu conceito ao visitar um museu, ler livros, ver filmes145. Um LLM congelado em seu checkpoint de treinamento não evolui com o mundo146.
O fato de humanos e LLMs compartilharem mecanismos estatísticos no processamento linguístico não implica que compartilhem compreensão147. A diferença reside na ancoragem causal e perceptual, na agência motivada e na continuidade experiencial148. Os LLMs são sistemas que aprenderam a imitar a competência linguística sem desenvolver as pré-condições cognitivas que a sustentam em humanos149.
No entanto, convém reconhecer um limite epistêmico no argumento anterior150. As quatro diferenças assinaladas (ancoragem multimodal, modelos causais, motivação intrínseca, aprendizagem contínua) descrevem condições externas observáveis, não estados internos de compreensão151. Enfrentamos aqui o clássico problema de outras mentes 152: não temos acesso direto à experiência subjetiva de nenhum sistema humano ou artificial além de nossa própria consciência153.
Quando afirmamos que uma criança “compreende” a palavra “bola” porque a viu, tocou e lançou, inferimos essa compreensão a partir de sua conduta coerente em contextos variados 154: pode pedir a bola, distingui-la de outros objetos, usá-la apropriadamente155. Mas a experiência fenomenológica da criança — o “que se sente” ao compreender — nos resulta inacessível156. O mesmo vale para os LLMs 157: podemos documentar suas falhas sistemáticas (fragilidade diante de mudanças de domínio, regressão a padrões frequentes), mas não podemos descartar categoricamente que exista alguma forma de “compreensão” emergente em suas camadas internas, distinta da humana mas funcional à sua maneira158.
Mais ainda: talvez os humanos também sejamos, em algum nível fundamental, aproximadores estatísticos sofisticados cuja “compreensão” não é qualitativamente distinta, mas apenas quantitativamente mais rica por nossa ancoragem multimodal e evolutiva159. Esta hipótese, embora especulativa, não pode ser refutada empiricamente de fora do sistema160.
Essa incerteza importa? Pragmaticamente, não para os fins da engenharia161. O que importa são as consequências mensuráveis162:
- Robustez: O sistema mantém coerência sob variações de contexto, domínio e formulação?163
- Adaptabilidade: Pode atualizar suas respostas diante de nova evidência sem retreinamento completo?164
- Ancoragem: Verifica suas afirmações contra fontes externas ou gera ficção verossímil?165
- Transparência: Podemos auditar suas decisões e corrigir vieses sistemáticos?166
Dessa perspectiva funcionalista, a pergunta relevante não é “compreende realmente?”, mas “comporta-se como se compreendesse de maneira confiável, adaptável e auditável?” 167A resposta atual é: em domínios fechados, muitas vezes sim; em domínios abertos ou mutáveis, sistematicamente não168.
Adotamos um agnosticismo pragmático sobre a compreensão interna dos LLMs169. Não afirmamos que careçam de toda forma de “entendimento”, mas dadas suas falhas observáveis, não cumprem critérios funcionais robustos de compreensão situada170. O peso da prova recai em demonstrar confiabilidade generalizável, não em postular estados internos inacessíveis171.
6. Conclusão: Rumo a uma Teoria Crítica da Geração Artificial
O programa de Turing apresenta a linguagem como procedimento e oferece a indistinguibilidade textual como critério pragmático 172; o de Chomsky a concebe como faculdade com restrições formais que explicam a produtividade estrutural à custa de abstrair o social 173; a IA generativa a trata como modelo estatístico-cultural capaz de capturar correlações e estilos sem ancoragem experiencial autônoma174. Estes três olhares não se excluem, mas tampouco se reduzem um ao outro175.
O projeto contemporâneo de gerar inteligência mediante aprendizagem estatística massiva revela um paradoxo fundacional 176: buscamos produzir aquilo que não sabemos definir177. O que é exatamente a inteligência que aspiramos a gerar? Capacidade de resolver problemas, adaptabilidade diante do imprevisto, compreensão situada, consciência fenomenológica? 178178178Cada critério proposto — teste de Turing, benchmarks acadêmicos, desempenho em tarefas específicas — captura dimensões parciais sem esgotar o fenômeno179. Aprendemos a gerar conduta inteligente em domínios delimitados, mas a pergunta de se isso constitui inteligência genuína ou simulação sofisticada permanece aberta — e talvez, de uma perspectiva pragmática, seja indecidível180.
Gerar texto não equivale a predizer o sentido 181: quando muito, participa de maneira limitada em sua negociação182. A aspiração a uma “predição perfeita” resulta não só inalcançável, mas conceitualmente errada diante de um objeto em constante mudança183. Por isso, inteligência não é sinônimo de linguagem 184184: a IA generativa funciona hoje como interface informática entre nossas intenções e a máquina, traduzindo instruções em operações mediante linguagens naturais ou formais185185185185. É uma competência estatística automatizada que simula coerência em espaços formais finitos sem horizonte semântico próprio no sentido de agência autônoma186186186186.
O horizonte mais promissor não consiste em “fazer passar” máquinas por humanas 187187187187, mas em codelimitar modelos que evoluam conosco, atentos à negociação permanente entre estrutura, cultura e novidade188188188188.
Medimos a inteligência artificial ali onde a predição tropeça e começa a interpretação 189: na adaptação situada, na ancoragem ao mundo e na responsabilidade pelas consequências do que é dito190.
Referências
Avramides, A. (2001). Other Minds. Routledge. Bender, E., & Koller, A. (2020).
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of
Data. ACL. Bender, E., Gebru, T., et al. (2021). On the Dangers of Stochastic Parrots. FAccT. Bybee, J. (2010). Language, Usage and Cognition. CUP.
Chomsky, N. (1957). Syntactic Structures. Mouton. Chomsky, N. (1965). Aspects of the Theory of Syntax. MIT Press. Clark, A. (1997). Being There. MIT
Press. Dennett, D. (1991). Consciousness Explained. Little, Brown. Floridi, L.
(2019). The Logic of Information. OUP. Halliday, M. A. K. (1978). Language
9
as Social Semiotic. Edward Arnold. Harnad, S. (1990). The Symbol Grounding
Problem. Physica D, 42(1–3), 335–346. Hopper, P. J. (1987). Emergent Grammar. BLS 13, 139–157. Hymes, D. (1972). On Communicative Competence.
In Pride & Holmes (eds.), Sociolinguistics. Lakoff, G. (1987). Women, Fire,
and Dangerous Things. U. Chicago Press. Lazaridou, A., Peysakhovich, A., &
Baroni, M. (2016). Multi‑Agent Cooperation and the Emergence of (Natural)
Language. ICLR. Lenneberg, E. (1967). Biological Foundations of Language.
Wiley. Mikolov, T., et al. (2013). Efficient Estimation of Word Representations
in Vector Space. arXiv. [Word2Vec] Mordatch, I., & Abbeel, P. (2018). Emergence of Grounded Compositional Language in Multi‑Agent Populations. AAAI.
Pennington, J., Socher, R., & Manning, C. (2014). GloVe: Global Vectors for
Word Representation. EMNLP. Peters, M., et al. (2018). Deep Contextualized
Word Representations. NAACL. [ELMo] Radford, A., et al. (2018). Improving
Language Understanding by Generative Pre-Training. OpenAI. [GPT] Schick,
T., Dwivedi‑Yu, J., et al. (2023). Toolformer: Language Models Can Teach
Themselves to Use Tools. arXiv. Yao, S., et al. (2023). ReAct: Synergizing
Reasoning and Acting in Language Models. ICLR. Zhou, B., et al. (2021). TimeDial: Temporal Commonsense Reasoning in Dialog. EMNLP. Marcus, G.,
& Davis, E. (2019). Rebooting AI. Pantheon. Searle, J. (1980). Minds, Brains,
and Programs. BBS, 3(3), 417–424. Tomasello, M. (2003). Constructing a
Language. Harvard. Turing, A. (1950). Computing Machinery and Intelligence.
Mind, 59(236), 433–460. Vaswani, A., et al. (2017). Attention Is All You Need.
NeurIPS. [Transformer architecture
Este artigo foi escrito em espanhol e traduzido para o inglês e português com o ChatGPT.
Descubra mais artigos de seu interesse!
Voltar atrás
