La máquina simbólica y la paradoja de generar inteligencia
Por Santiago Komadina Geffroy
Enero 12, 2026
- La máquina simbólica y la paradoja de generar inteligencia
- 1. Turing y el Lenguaje como Procedimiento
- 2. Chomsky, los Lenguajes Formales y su Equivalencia con Máquinas
- 3. Convergencia y Ruptura: Generar No Es Comprender
- 4. La Lenguaje entre Estructura, Símbolo y Cultura
- 5. Más Allá del Test de Turing: Criterios y Límites Contemporáneos
- 6. Conclusión: Hacia una Teoría Crítica de la Generación Artificial
- Referencias
La inteligencia artificial moderna surge del cruce entre informática, matemática y lingüística. En su base operan la lógica y los lenguajes formales; sin embargo, reducir la inteligencia a lo lógico-formal ha mostrado límites persistentes. La IA simbólica por reglas no alcanzó una inteligencia general: manipular símbolos no garantizó comprenderlos.
En humanos, el lenguaje estructura y vehicula el pensamiento sin agotarlo; en sistemas artificiales, en cambio, tendemos a equiparar generación lingüística con inteligencia. En 1950, Turing desplaza la pregunta “¿Pueden pensar las máquinas?“ a un criterio de conducta textual (el Imitation Game). Más de siete décadas después, los modelos generativos —de GPT a Gemini o Claude— parecen cumplir ese criterio de indistinguibilidad en amplios dominios.
El éxito, pero, reactiva la cuestión: ¿es la generación lingüística una forma de pensamiento o un simulacro estadístico que confunde fluidez con entendimiento?
Aquí proponemos una lectura cruzada entre la máquina de Turing y la gramática generativa de Chomsky para iluminar la promesa y el límite de la IA generativa: generar lenguaje sin necesariamente comprenderlo. Más aún: la ironía contemporánea consiste en que intentamos generar inteligencia sin comprender del todo qué es la inteligencia misma; aspiramos a producir algorítmicamente aquello que apenas podemos definir conceptualmente.
1. Turing y el Lenguaje como Procedimiento
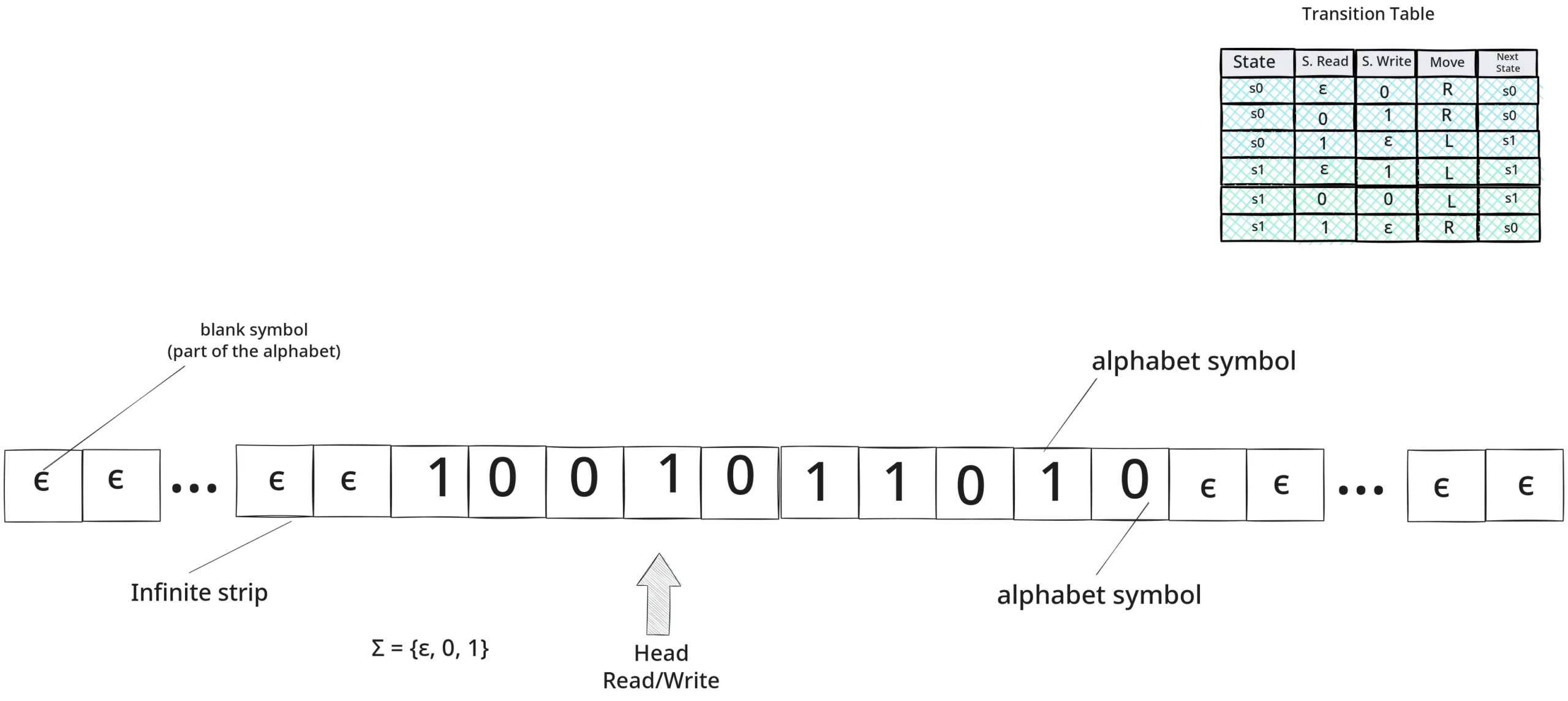
La máquina de Turing (1936) formaliza la computabilidad. En su definición estándar, una MT es una 7‑tupla:
Donde (Q) es el conjunto de estados, (Σ) el alfabeto de entrada, (Γ) el alfabeto de cinta, (ff) la función de transición, (q_0) el estado inicial y (q_“acepta”,q_“rechaza”) los estados de parada. Con una cinta teóricamente infinita y un conjunto finito de reglas, Turing muestra que todo algoritmo efectivo es, en principio, simulable. En términos de teoría de la computación, conviene distinguir decidibilidad de enumerabilidad: hay lenguajes para los que existe un procedimiento que decide aceptación o rechazo en tiempo finito (decidibles), y otros para los que solo podemos enumerar los elementos aceptados sin garantía de detenernos en los rechazados (recursivamente enumerables). La Tesis de Church–Turing no es un teorema matemático formal —relaciona un concepto informal (“cálculo efectivo”) con uno formal (máquina de Turing)— pero constituye un principio fundamental universalmente aceptado tras casi un siglo de evidencia acumulada: todo cálculo efectivo que podamos describir con claridad es simulable por una máquina de Turing.
Ello habilita el puente con la teoría de lenguajes y autómatas: cada sistema 1 formal puede verse como un dispositivo que genera o reconoce cadenas bien formadas. El test de Turing traslada la computación al teatro del lenguaje: si la interacción textual es indistinguible de la humana, la máquina pasa por “pensante”. Los LLMs contemporáneos encarnan esta visión procedimental: hablar como calcular.
2. Chomsky, los Lenguajes Formales y su Equivalencia con Máquinas
La Jerarquía de Chomsky ordena gramáticas por su poder generativo y las correlaciona con clases de autómatas:

Nota sobre Tipo 1: Un Autómata Linealmente Acotado (LBA) es esencialmente una máquina de Turing cuya cinta queda restringida a un múltiplo lineal del tamaño de la entrada. Esta limitación captura la familia de lenguajes sensibles al contexto, donde las derivaciones pueden depender del entorno, pero siguen sujetas a un recurso de memoria acotado por la entrada.
En notación estándar, el lenguaje reconocido por un autómata $(M)$ es:
La gramática generativa describe un dispositivo capaz de producir secuencias bien formadas. Chomsky la interpreta como facultad cognitiva; Turing, como caracterización computacional.
La productividad infinita de la gramática generativa —la capacidad de generar y comprender un número ilimitado de oraciones a partir de reglas finitas— inspiró la intuición de que los sistemas formales podían capturar la esencia del lenguaje. Durante décadas, la IA simbólica intentó codificar esas reglas explícitamente: gramáticas de rasgos, parsers sintácticos, ontologías semánticas. El programa asumió que describir la competencia lingüística equivalía a implementarla.
La IA moderna hereda la fuerte intuición de que mente y lenguaje se modelan como manipulación simbólica regida por reglas.
Sin embargo, el giro contemporáneo invierte el paradigma: las reglas ya no se programan, se aprenden. Los modelos neuronales son autómatas paramétricos cuya complejidad expresiva puede alcanzar la de lenguajes de Tipo 0, pero inducidos a partir de datos en lugar de especificados por lingüistas. Donde Chomsky postuló universales innatos, los LLMs descubren regularidades estadísticas en corpora masivos. Donde la gramática generativa buscaba competencia subyacente (el conocimiento tácito del hablante), los transformers capturan performance observable (las regularidades del uso efectivo).
Esta ruptura metodológica tiene consecuencias profundas: ya no formalizamos el lenguaje para luego implementarlo; entrenamos sistemas para que induzcan sus propias regularidades. El resultado es una gramática implícita, distribuida en millones de parámetros, que puede generar texto fluido sin poseer un modelo explícito de sintaxis o semántica. Hemos aprendido a generar inteligencia lingüística sin necesidad de especificarla; la pregunta pendiente es si esa generación constituye genuina comprensión o mera simulación sofisticada.
La elegancia de la correspondencia formal no debe confundirse con una ontología del significado: que una clase de lenguajes sea representable por un autómata no implica que el uso humano del lenguaje se agote en esa representación. Más aún: que un sistema neural simule competencia lingüística no implica que replique los mecanismos cognitivos subyacentes.
3. Convergencia y Ruptura: Generar No Es Comprender
Los LLMs aproximan distribuciones de probabilidad $p(w_t|w_{t-1})$ sobre secuencias mediante arquitecturas neuronales (transformers) que, en principio, pueden modelar la complejidad de lenguajes de Tipo 0 en la jerarquía de Chomsky, si bien sin implementar reglas de reescritura explícitas. A diferencia de las gramáticas formales que operan mediante sistemas de reescritura simbólica, los LLMs son aproximadores universales que aprenden patrones de los datos: una sintaxis estadística entrenada en corpora masivos.
Alcanzan fluidez y coherencia local sin garantía de semántica interna. Si la gramática chomskyana apuntaba a la competencia (conocimiento subyacente), los LLMs capturan sobre todo performance (regularidades de uso) y señales de mundo destiladas del texto.
En la tradición chomskyana, la gramática es ante todo una facultad mental: un sistema biológico con restricciones innatas que explica cómo los humanos adquirimos y manipulamos estructuras sintácticas. En la IA generativa, en contraste, “gramática“ es el nombre operacional de una función de probabilidad sobre cadenas, parametrizada por millones o miles de millones de pesos que ajustan la verosimilitud de cada token en contexto. Ambas perspectivas comparten una intuición formal, pero difieren en su ontología: la primera remite a mecanismos cognitivos; la segunda, a procedimientos estadísticos. Resultado: una sintaxis estadística sin intencionalidad. Generación no es igual a comprensión. La coherencia formal no implica necesariamente anclaje referencial ni visión de mundo en el sentido humano.
La lengua natural es ambigua por design. La lógica formal aspira a eliminar la ambigüedad; el uso lingüístico prospera en ella. ¿Cómo obtienen “sentido“ los modelos sin desambiguación total? Por densidad relacional: el significado se aproxima como posición en un espacio de relaciones. Y es justamente esta dimensión funcional la que explota la maravilla técnica de la lingüística computacional: los embeddings. Estos no son más que representaciones vectoriales de palabras aprendidas por un modelo estadístico. Tras “aprender“ sobre enormes corpora de texto, los modelos de embeddings capturan tanto semántica como relaciones sintácticas. Tener vectores para las palabras permite entonces realizar operaciones matemáticas sobre las palabras y sus sentidos. Así hemos logrado traducir cadenas de símbolos que para nosotros, humanos, tienen sentido, a una realidad computable. El “sentido“ artificial proviene de aquí.
Sin embargo, su evolución ilustra el paso de una semántica estática a una dinámica:
- Word2Vec y GloVe (2013-2014): Cada palabra recibe un único vector basado en coocorrencias en el corpus. La famosa analogía vectorial “rey – hombre + mujer = reina“ funciona porque las operaciones algébricas capturan relaciones semánticas recurrentes. Sin embargo, estos modelos no distinguen polisemia: “banco“ (institución financiera) y “banco“ (asiento) comparten el mismo vector.
- Embeddings contextuales (ELMO, BERT, 2018): Cada palabra recibe un vector distinto según su contexto. “Banco“ en “fui al banco a depositar“ y “me senté en el banco del parque“ generan representaciones diferentes. El modelo atiende al entorno para desambiguar.
- Transformers generativos (GPT, 2018-): Los mecanismos de atención multi-cabeza permiten que cada token module dinámicamente su representación en función de todos los demás tokens relevantes en la secuencia, integrando dependencias de largo alcance que imitan concordancia gramatical, referencias anafóricas y coherencia temática.
Los embeddings condensan regularidades semánticas y sintácticas en vectores de alta dimensión cuya proximidad refleja patrones de coocurrencia y transformaciones contextuales; no dicen lo que una cosa es, sino con qué tiende a aparecer y cómo se modifica al combinarse. Los mecanismos de atención permiten que cada decisión condicione dinámicamente un token respecto a otros potencialmente distantes, integrando dependencias de largo alcance que imitan acuerdos y relaciones anafóricas. La llamada interpretabilidad mecanicista ha identificado cabezas y circuitos sensibles a rasgos gramaticales y de estilo, prueba de que los modelos capturan estructura estadística útil.
Sin embargo, las analogías vectoriales clásicas funcionan en dominios frecuentes del corpus, pero se rompen bajo cambio de dominio o polisemias activas: al pasar de geografía histórica a geopolítica contemporánea, o de lenguaje cotidiano a jerga técnica, la vecindad semántica varía y los vectores arrastran asociaciones espurias. El fenómeno ilustra una fortaleza (capturar regularidades locales) y un límite: la fragilidad ante traslaciones conceptuales que exigen reanclar significados.
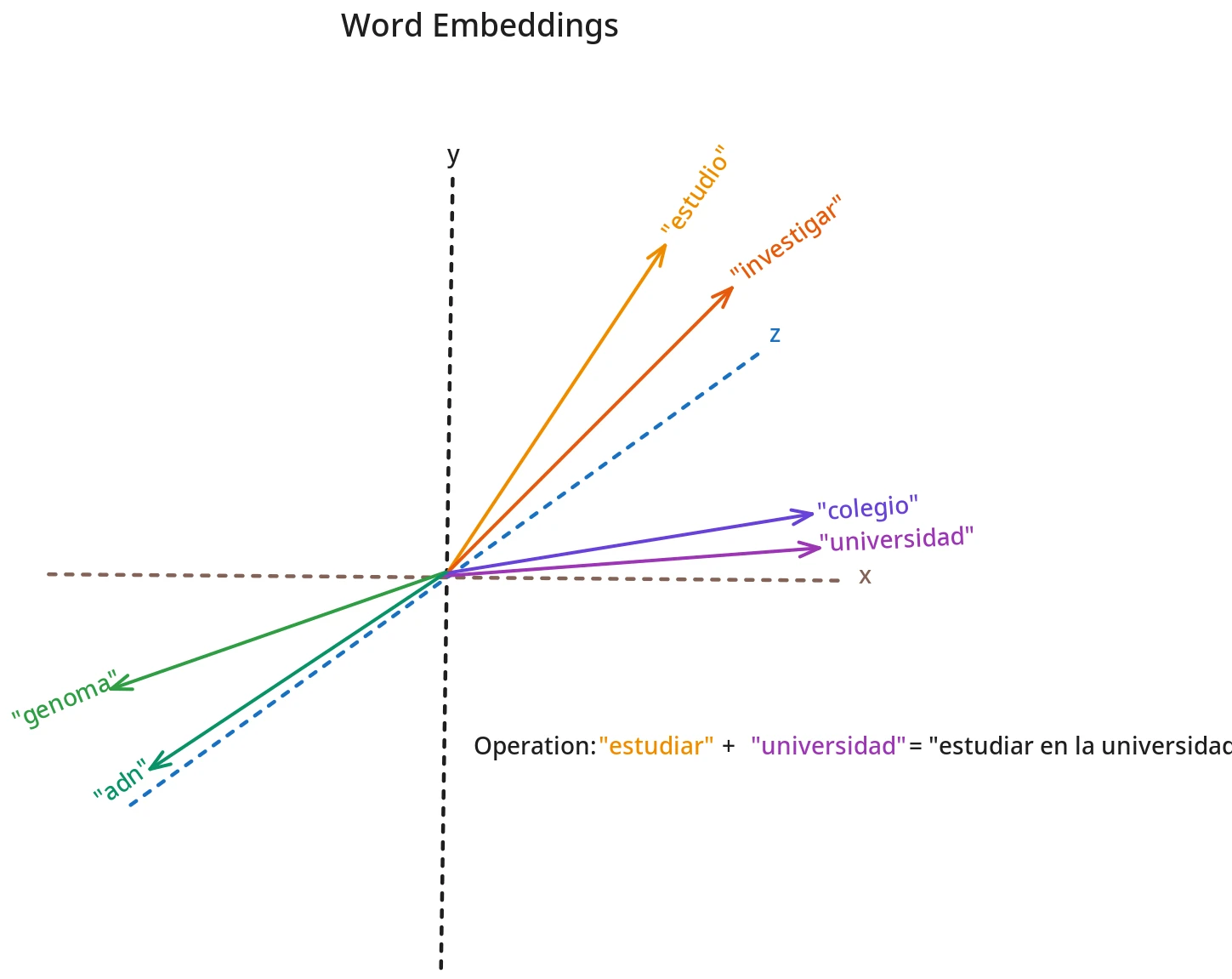
Siguiendo esta lógica, cada palabra de nuestro vocabulario tiene un vector de embedding aprendido que la posiciona deterministicamente en su espacio latente (la dimensionalidad = al tamaño del vocabulario). De esta manera, vectores similares indican relaciones de proximidad semántica/sintáctica. Además, dada la naturaleza computacional de estos, podemos realizar operaciones matemáticas sobre “las palabras“.
Disponer de representaciones ricas es condición necesaria, pero no suficiente, para la comprensión situada. Lo que emerge es una competencia estadística poderosa, pero sin compromiso ontológico directo con referentes en el sentido de experiencia perceptual autónoma —aunque modelos multimodales recientes (CLIP, GPT-4V, Gemini) empiezan a integrar señales visuales y textuales, estableciendo formas incipientes de anclaje perceptual.
4. La Lenguaje entre Estructura, Símbolo y Cultura
El logro de Chomsky fue formalizar el lenguaje como sistema de reglas; su costo fue abstraer la dimensión social. La sociolingüística, la pragmática y la lingüística basada en el uso nos recuerdan que el lenguaje se negocia en comunidades de práctica. Los LLMs reincorporan cultura por vía estadística: absorben ideologías, sesgos, registros y dialectos sin conciencia. Producen una cultura sintética: reflejo de distribuciones históricas de nuestras voces, a veces con amplificación de asimetrías.
Decir que el lenguaje es simbólico es afirmar que sus unidades significan por convención y relación (no por semejanza física con sus referentes). Esta arbitrariedad permite que el mismo soporte (texto, audio, código) exprese infinidad de contenidos y estilos. Por eso es posible modelar con un único formalismo grandes familias de prácticas: lenguas naturales con sus dialectos, jerga técnica, código, fórmulas, notación musical… La dimensión simbólica del lenguaje es la que hace escalable el aprendizaje a partir de corpora heterogéneos.
Del hecho de que el lenguaje sea simbólico no se sigue que exista una Gramática Universal operativa capaz de reconocer todo por reglas explícitas. Buscamos el formalismo de la inteligencia (el “artificial“), pero cuando formalizamos sin residuo perdemos ambigüedad, precisamente el recurso que explota el lenguaje vivo.
Que la lengua esté viva no implica anarquía: implica variación regulada. Las reglas (convenciones) se aprenden y ajustan por el uso. Los LLMs aprenden una instantánea de esa variación: un modelo entrenado hasta 2023 no conoce el idiolecto de 2025 sin actualización. Son gramáticas congeladas en su momento de entrenamiento: capturan regularidades históricas del corpus, pero no su dinámica transformadora posterior sin retrainings, fine-tuning o mecanismos de actualización como retrieval-augmented generation (RAG).
Los modelos en gran escala absorben diversidad cultural sin postular universales explícitos, y por ello pueden simular consistencias locales en dominios relativamente cerrados al mismo tiempo que exhiben fallas de anclaje cuando cambian prácticas, referentes o normas. Su notable eficacia funcional no constituye evidencia de comprensión: revela, antes, el poder de las correlaciones. Del mismo modo, los sesgos que reproducen no son un simple “bug“ corregible a posteriori, sino un efecto cultural de la estadística: la destilación de distribuciones históricas con sus asimetrías.
- Simulan consistencia en dominios cerrados, pero fallan en anclaje cuando cambian prácticas, referentes o normas.
- Su éxito funcional no prueba comprensión; su sesgo no es un “bug“ meramente técnico, sino un efecto cultural de la estadística.
5. Más Allá del Test de Turing: Criterios y Límites Contemporáneos
Hoy evaluamos sistemas con pruebas complementarias: Winograd/Winoground (referencias), ARC (abstracción y composición), BIG-bench, MMLU (conocimiento y razonamiento), e incluso ARC-AGI (el Santo Grial de la IA actual, ser general), entre otros. El panorama es mixto: avances notables en competencia estadística conviven con límites en generalización sistemática, anclaje semántico y adaptación situada. El salto de predicción a interpretación sigue siendo el cuello de botella.
En los últimos años surgieron evaluaciones de anclaje (temporal, factual y multimodal) y protocolos de uso de herramientas que conectan el modelo con buscadores, bases de datos o calculadoras. Estos enfoques mejoran la precisión cuando la tarea exige verificar o actualizar hechos, pero también transfieren parte de la inteligencia a la orquestación: decidir cuándo consultar, qué fuente utilizar y cómo reconciliar evidencias en conflicto. En paralelo, trabajos sobre comunicación emergente en entornos de aprendizaje por refuerzo demuestran que los agentes pueden desarrollar códigos útiles para sus fines, aunque raramente composicionales y transferibles a prácticas humanas sin tutoría.
Un crítico podría argumentar: “Los bebés también adquieren la lenguaje por exposición masiva a input lingüístico, detectando patrones estadísticos en el habla de su entorno. Si los humanos aprendemos así y desarrollamos comprensión, ¿por qué los LLMs, que hacen esencialmente lo mismo con más datos, no la tendrían?“
La objeción es seria y merece una respuesta cuidadosa. Las diferencias no son meramente cuantitativas (más datos, más parámetros), sino cualitativas:
- Anclaje multimodal: Los niños aprenden lenguaje simultáneamente con experiencia perceptual directa del mundo. Cuando oyen “pelota“, ven, tocan, lanzan pelotas. La palabra se ancla en experiencias sensorio-motoras recurrentes. Los LLMs puramente textuales carecen de esta triangulación; modelos multimodales recientes (GPT-4V, Gemini) comienzan a cerrar esta brecha, pero todavía sin la riqueza de la experiencia corpórea.
- Modelos causales del mundo: Los humanos desarrollan física intuitiva (los objetos no desaparecen, caen), psicología intuitiva (los agentes tienen intenciones), biología intuitiva (los seres vivos crecen y mueren). Estos modelos causales estructuran la comprensión lingüística. Un LLM puede predecir que “si sueltas un vaso, se rompe“, pero no porque entienda gravedad o fragilidad, sino porque esa secuencia es frecuente en sus datos.
- Motivación intrínseca y experiencia situada: Los niños aprenden lenguaje en contextos con propósito comunicativo real: pedir, compartir atención, negociar. Cada acto lingüístico tiene consecuencias en el mundo social. Los LLMs son entrenados en un objetivo técnico (predecir el siguiente token) sin agencia ni consecuencia existencial de sus “actos de habla“.
- Aprendizaje continuo y adaptación: Los humanos actualizan constantemente su comprensión del lenguaje en interacción con el entorno cambiante. Un niño que aprende “dinosaurio“ ajusta su concepto al visitar un museo, leer libros, ver películas. Un LLM congelado en su checkpoint de entrenamiento no evoluciona con el mundo.
Que humanos y LLMs compartan mecanismos estadísticos en el procesamiento lingüístico no implica que compartan comprensión. La diferencia radica en el anclaje causal y perceptual, la agencia motivada y la continuidad experiencial. Los LLMs son sistemas que han aprendido a imitar la competencia lingüística sin desarrollar las precondiciones cognitivas que la sostienen en humanos.
No obstante, cabe reconocer un límite epistémico al argumento anterior. Las cuatro diferencias señaladas (anclaje multimodal, modelos causales, motivación intrínseca, aprendizaje continuo) describen condiciones externas observables, no estados internos de comprensión. Enfrentamos aquí el clásico problema de otras mentes: no tenemos acceso directo a la experiencia subjetiva de ningún sistema humano o artificial más allá de nuestra propia conciencia.
Cuando afirmamos que un niño “comprende“ la palabra “pelota“ porque la ha visto, tocado y lanzado, inferimos esa comprensión a partir de su conducta coherente en contextos variados: puede pedir la pelota, distinguirla de otros objetos, usarla apropiadamente. Pero la experiencia fenomenológica del niño —el “qué se siente“ al comprender— nos resulta inaccesible. Lo mismo aplica a los LLMs: podemos documentar sus fallas sistemáticas (fragilidad ante cambios de dominio, regresión a patrones frecuentes), pero no podemos descartar categóricamente que exista alguna forma de “comprensión“ emergente en sus capas internas, distinta de la humana pero funcional a su manera. Más aún: tal vez los humanos también seamos, en algún nivel fundamental, aproximadores estadísticos sofisticados cuya “comprensión“ no es cualitativamente distinta, sino solo cuantitativamente más rica por nuestro anclaje multimodal y evolutivo. Esta hipótesis, aunque especulativa, no puede ser refutada empíricamente desde fuera del sistema.
¿Importa esta incertidumbre? Pragmáticamente, no para los fines de la ingeniería. Lo que importa son las consecuencias mensurables:
- Robustez: ¿Mantiene el sistema coherencia bajo variaciones de contexto, dominio y formulación?
- Adaptabilidad: ¿Puede actualizar sus respuestas ante nueva evidencia sin retrenamiento completo?
- Anclaje: ¿Verifica sus afirmaciones contra fuentes externas o genera ficción verosímil?
- Transparencia: ¿Podemos auditar sus decisiones y corregir sesgos sistemáticos?
Desde esta perspectiva funcionalista, la pregunta relevante no es “¿comprende verdaderamente?“, sino “¿se comporta como si comprendiera de manera confiable, adaptable y auditable?“ La respuesta actual es: en dominios cerrados, a menudo sí; en dominios abiertos o cambiantes, sistemáticamente no. Adoptamos un agnosticismo pragmático sobre la comprensión interna de los LLMs. No afirmamos que carezcan de toda forma de “entendimiento“, pero dadas sus fallas observables, no cumplen criterios funcionales robustos de comprensión situada. El peso de la prueba recae en demostrar confiabilidad generalizable, no en postular estados internos inaccesibles.
6. Conclusión: Hacia una Teoría Crítica de la Generación Artificial
El programa de Turing presenta el lenguaje como un procedimiento y ofrece la indistinguibilidad textual como criterio pragmático; el de Chomsky lo concibe como una facultad con restricciones formales que explican la productividad estructural a costa de abstraer lo social; la IA generativa lo trata como un modelo estadístico-cultural capaz de capturar correlaciones y estilos sin anclaje experiencial autónomo. Estas tres ópticas no se excluyen, pero tampoco se reducen una a la otra.
El proyecto contemporáneo de generar inteligencia mediante aprendizaje estadístico masivo revela una paradoja fundacional: buscamos producir aquello que no sabemos definir. ¿Qué es exactamente la inteligencia que aspiramos a generar? ¿Capacidad de resolver problemas, adaptabilidad ante lo imprevisto, comprensión situada, conciencia fenomenológica? Cada criterio propuesto —test de Turing, benchmarks académicos, desempeño en tareas específicas— captura dimensiones parciales sin agotar el fenómeno. Hemos aprendido a generar conducta inteligente en dominios delimitados, pero la pregunta de si ello constituye inteligencia genuina o simulación sofisticada permanece abierta —y quizás, desde una perspectiva pragmática, es indecidible.
Generar texto no equivale a predecir el sentido: a lo sumo, participa en su negociación de manera limitada. La aspiración a una “predicción perfecta“ resulta no solo inalcanzable, sino conceptualmente errada ante un objeto en constante cambio. Por ello, inteligencia no es sinónimo de lenguaje: la IA generativa funciona hoy como una interfaz informática entre nuestras intenciones y la máquina, traduciendo instrucciones en operaciones mediante lenguajes naturales o formales. Es una competencia estadística automatizada que simula coherencia en espacios formales finitos sin horizonte semántico propio en el sentido de agencia autónoma.
El horizonte más promisorio no consiste en “hacer pasar“ máquinas por humanas, sino en codiseñar modelos que evolucionen con nosotros, atentos a la negociación permanente entre estructura, cultura y novedad. La “predicción perfecta” es no solo inalcanzable: es conceptualmente errónea para un sistema en permanente cambio.
La IA generativa es, hoy, una interfaz informática entre mente humana y máquina: traduce intenciones difusas en operaciones mediante lenguaje natural o formal. Es una competencia estadística automatizada útil, que simula coherencia en espacios formales finitos sin horizonte semántico propio. El programa prometedor no es “hacer pasar” máquinas por humanas, sino co‑diseñar modelos que evolucionen con nosotros, atentos a la negociación entre estructura, cultura y novedad.
Midamos la inteligencia artificial allí donde la predicción tropieza y comienza la interpretación: en la adaptación situada, el anclaje al mundo y la responsabilidad por las consecuencias de lo dicho.
Referencias
Avramides, A. (2001). Other Minds. Routledge. Bender, E., & Koller, A. (2020).
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of
Data. ACL. Bender, E., Gebru, T., et al. (2021). On the Dangers of Stochastic Parrots. FAccT. Bybee, J. (2010). Language, Usage and Cognition. CUP.
Chomsky, N. (1957). Syntactic Structures. Mouton. Chomsky, N. (1965). Aspects of the Theory of Syntax. MIT Press. Clark, A. (1997). Being There. MIT
Press. Dennett, D. (1991). Consciousness Explained. Little, Brown. Floridi, L.
(2019). The Logic of Information. OUP. Halliday, M. A. K. (1978). Language 9
as Social Semiotic. Edward Arnold. Harnad, S. (1990). The Symbol Grounding
Problem. Physica D, 42(1–3), 335–346. Hopper, P. J. (1987). Emergent Grammar. BLS 13, 139–157. Hymes, D. (1972). On Communicative Competence.
In Pride & Holmes (eds.), Sociolinguistics. Lakoff, G. (1987). Women, Fire, and Dangerous Things. U. Chicago Press. Lazaridou, A., Peysakhovich, A., & Baroni, M. (2016). Multi‑Agent Cooperation and the Emergence of (Natural) Language. ICLR. Lenneberg, E. (1967). Biological Foundations of Language.
Wiley. Mikolov, T., et al. (2013). Efficient Estimation of Word Representations
in Vector Space. arXiv. [Word2Vec] Mordatch, I., & Abbeel, P. (2018). Emergence of Grounded Compositional Language in Multi‑Agent Populations. AAAI.
Pennington, J., Socher, R., & Manning, C. (2014). GloVe: Global Vectors for
Word Representation. EMNLP. Peters, M., et al. (2018). Deep Contextualized
Word Representations. NAACL. [ELMo] Radford, A., et al. (2018). Improving
Language Understanding by Generative Pre-Training. OpenAI. [GPT] Schick,
T., Dwivedi‑Yu, J., et al. (2023). Toolformer: Language Models Can Teach
Themselves to Use Tools. arXiv. Yao, S., et al. (2023). ReAct: Synergizing
Reasoning and Acting in Language Models. ICLR. Zhou, B., et al. (2021). TimeDial: Temporal Commonsense Reasoning in Dialog. EMNLP. Marcus, G.,
& Davis, E. (2019). Rebooting AI. Pantheon. Searle, J. (1980). Minds, Brains,
and Programs. BBS, 3(3), 417–424. Tomasello, M. (2003). Constructing a
Language. Harvard. Turing, A. (1950). Computing Machinery and Intelligence.
Mind, 59(236), 433–460. Vaswani, A., et al. (2017). Attention Is All You Need.
NeurIPS. [Transformer architecture
Este artículo fue escrito en español y traducido a inglés y portugués con ayuda de ChatGPT.
¡Descubre más artículos de tu interés!
Volver atrás
